CHAPTER
NUMPY VECTORS AND CACHE CONSIDERATIONS
The following figure refers to numpy_vector_2.py where I vary the vector size that I’m dealing with by taking slices out of each numpy vector. We can see that the run time on the laptop (blue) and i3 desktop (orange) hits a sweet spot around an array length of 20,000 items.
Oddly this represents a total of about 640k of data between the two arrays, way below the 3MB L2 cache on both of my machines.
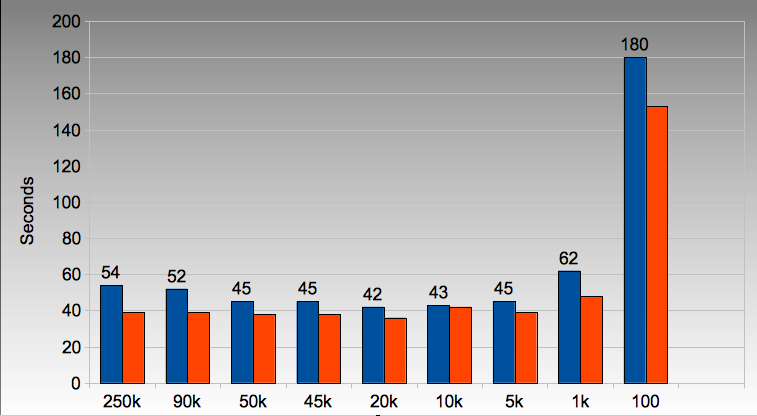
Figure 17.1: Array and cache size considerations
The code I’ve used looks like:
def calculate_z_numpy(q_full, maxiter, z_full):
output=np.resize(np.array(0,), q_full.shape)
#STEP_SIZE = len(q_full) # 54s for 250,000
#STEP_SIZE = 90000 # 52
#STEP_SIZE = 50000 # 45s
#STEP_SIZE = 45000 # 45s
STEP_SIZE=20000 # 42s # roughly this looks optimal on Macbook and dual core desktop i3
#STEP_SIZE = 10000 # 43s
#STEP_SIZE = 5000 # 45s
#STEP_SIZE = 1000 # 1min02
#STEP_SIZE = 100 # 3mins
print "STEP_SIZE", STEP_SIZE
for step in range(0, len(q_full), STEP_SIZE):
z = z_full[step:step+STEP_SIZE]
q = q_full[step:step+STEP_SIZE]
for iteration in range(maxiter):
z = z*z + q
done = np.greater(abs(z), 2.0)
q = np.where(done,0+0j, q)
z = np.where(done,0+0j, z)
output[step:step+STEP_SIZE] = np.where(done, iteration, output[step:step+STEP_SIZE])
return output