Chapter 3
3.1 Core Data Types
Core data types are those data types that are viewed as fundamental to life in IT. They are the building blocks used to create most other data types. If you graduated high school and have looked at the labels affixed to advertisements you receive in the mail, you are familiar with all of them. You just may not realize it. Let us start simple and work our way forward.
Almost all computer languages have what is called a character data type. This is a data type which holds exactly one character. A character is one entity out of the character encoding set used by the platform. There are many character encoding sets. The most common set is the ANSI (American National Standards Institute) set called ASCII (American Standard Code for Information Interchange). Many IBM mainframe computers use EBCDIC (Extended Binary Coded Decimal Interchange Code). An encoding set gaining ground with the Java programming language is Unicode. Don’t delve too deeply into what these are until you have to. At some point, much further along in your career, you will encounter a situation where you have to transfer character data from one set to another, but you are not at that point yet. There are also tools that can be obtained to do the transformation for you.
A character is a single value out of one of these sets. The character may or may not be printable. Some character entries are left undefined in some of these sets to allow graphics developers and security people to put in their own meanings. Basically, there are printable characters, like the letters in a word or the numbers you see written, control characters and printable control characters.
Printable control characters are the easiest to explain. Things like TAB, carriage return, line feed, etc. They control the placement of characters when displaying or printing.
The other control characters mostly have to do with IO (Input Output) operations.
There is a bunch of them to handle communications via a serial connection or modem. Some of you may still access the Internet via a dial-up connection so you have “seen” some of these characters in operation when you initiate your connection. The other characters have to do with file operations, most notably EOF (End of File). This is a marker used by many operating systems to indicate there is nothing more to be read from a file.
You may never actually use all characters in a character set, but at one time they all had a specific purpose. Most books covering the Assembler language for your platform will have a chart for the native character set and its values.
Numeric data types get interesting because there are many and the names have different meanings on different platforms. The most common type is the Integer data type. When this value is signed, it can contain any whole number, positive or negative.
When it is unsigned, it can only contain zero and what are called “the counting numbers.” It does not natively store any fractional amounts.
Remember all of the fun you had learning fractions back in school? When you learned that 3/4 = 0.75 and you thought you could just use a calculator for everything, then the instructor tossed out problems using 1/3, which was an infinitely repeating decimal on your calculator, and you couldn’t get the same answer as the students who actually worked the problem out by hand? Fractional values have several categories of data types. Within those categories are many physical data types. Every one of these physical data types has a precision problem. In this case, precision refers to the number of digits to the right of the decimal point that can be stored accurately. You are not ready to go into a discussion on precision, nor will it happen in this book. You do need to be aware of why some of these data types won’t work for your logic.
You will hear programming types toss around various generic names for these data types: Float, Real, Single and Double. In many languages, Float, Real and Single are synonyms. Depending on how the code was compiled, they could all mean Double. You will also find a host of other data types designed to provide limited fractional capabilities in a smaller space, faster, but having more of a precision limitation. Some names you will find used for these types is Zoned Decimal, Packed Decimal and Scaled Integer. Each one serves a purpose. Both Zoned Decimal and Scaled Integer are in wide use even today. Packed decimal is used only by places which started using it in the 1970s and usually those are IBM mainframe shops. That platform provided built in OS and hardware support for Packed Decimal math, making the data type one of the better choices on it.
As a general rule, the Float, Real and Single data types, depending on what floating point standard is used, give you at most four digits of precision to the right of the decimal place. While they store many more, those are all subject to rounding errors. I’ve yet to see a Double implementation that didn’t give you at least six digits and some give you eight. Hence the full name Double Precision and the original name for Float/Real was Single Precision.
Each of these data types is a trade off between speed, storage space, precision and maximum value. To gain digits of precision to the right of the decimal place, you give up maximum value on the left. From a disk storage perspective, scaled integer tends to be the most efficient. This is why you see most database products storing floating point data in a scaled integer data type. Scaled integer data types can be brutal to do multiplication and division with, hence, most database products convert the scaled integer to some form of float upon retreval.
3.2 Data Type Sizes
To understand a little more about precision, you need to understand a little about data type sizes. Each data type has a predefined size when it is used by a programming language. Each language can, and sometimes does, use a different size from all others.
The smallest entity addressable on any computer system I have worked with is a bit. Many languages let you access bits directly, but few let you declare variables one bit in size. What they usually do is let you declare a data type of some other type, then name each of the bits as part of a structure. Bit fields can only have a value of On or Off (0 or 1). They are quite useful as boolean variables that can only have True or False (On or Off) states.
In today’s world, most computer systems will define some data types to be one byte in size. A byte is usually 8-bits on today’s systems. This was not always the case. In the old days of 4-bit computer systems, some bytes were only 4-bits wide. We are already seeing a shift in modern computer languages towards making the smallest addressable variable 16-bits. In the future, I expect that this fundamental definition will change to be at least 32-bits. Not because of any particular need from the programming community, but because the easiest method of addressing larger amounts of memory is to increase the minimum addressable size. The same number of addresses can be used to address a much larger quantity of memory.
Many programming languages implement the character data type as a byte. This meets the needs of ASCII and EBCDIC coding sets. It does not meet the needs of the Unicode set, which requires a minimum of 16-bits. Each character is stored as a binary value, which is a subscript into the encoding table provided by either the programming language or the operating system. (We will talk about tables in a little bit.)
What seems to be something of a standard these days is an Integer data type being defined as 16-bits. A long version of this tends to be 32-bits and a quad version, 64-bits. Translated, that is 2-bytes, 4-bytes and 8-bytes, respectively. Some languages and databases let you declare a Tiny Int, which is only 1-byte in size. A Tiny Int typically is used to store things like a month or a day from a date structure. (We will cover structures a little later in this chapter as well.)
Single precision floating point data types tend to be 4-bytes in size on most platforms. The actual encoding method used differs with each language and platform, but the size tends to be pretty consistent. Double precision floating point data types tend to be 8-bytes in size. Once again, encoding schemas very.
All bets are off when it comes to Zoned Decimal, Packed Decimal and Scaled Integer. Some platforms and databases allow for a scaled integer to be a dynamic number of bytes in size. Packed decimal has a standard, but it isn’t always followed. Zoned decimal tends to be a varying number of bytes for the number of digits being stored.
I’ve been tossing around the Packed Decimal and Zoned Decimal terms, so perhaps I should define it for you. For most of the computers you work with, a byte is defined as 8-bits. Half of that (4-bits) is called a “nibble.” Yes, people who come up with names in the geek world like to have a little fun. They also like to double things. A byte is two nibbles, a word is two bytes, a long is two words, etc. Because storage was very expensive early on, compiler developers and language designers came up with interesting ways to save space for numbers. They decided to start using the nibbles differently.
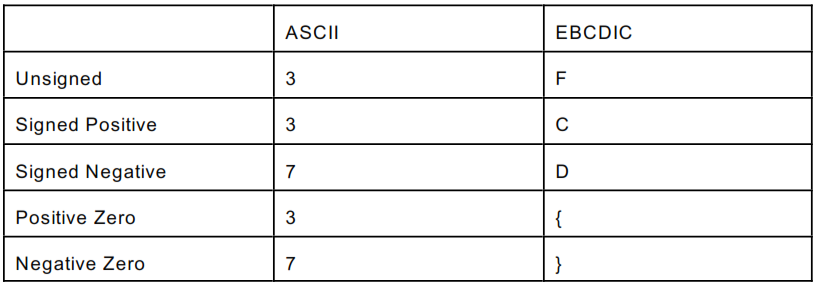
Zoned Decimal might have come first. It makes sense if it did, but it doesn’t matter. This was a method of storing numeric data in character format, one character for each digit. IBM had EBCDIC and the rest of us had ASCII. The number 789 was F7 F8 F9 when stored in EBCDIC but 373839 when stored in ASCII. Both formats were directly printable and the COBOL language provided libraries that allowed you to do math with them. This language introduced us to the phrase “assumed decimal.” When you were declaring a Zoned Decimal variable in COBOL, it was declared something like PIC 9(3) which translated to 3 Zoned Decimal digits. If you needed decimal points for financial statements, things would get declared along the lines of PIC 9(5)V99 where the V indicated the assumed decimal. We say it was assumed because it was never stored. I should also point out that the leading letter for the last digit had a method to its madness.
You have been reading an excerpt. Please visit http://www.theminimumyouneedtoknow.com to learn more about the series and to find out how to purchase books by this author.
Reads:
133
Pages:
127
Published:
Jan 2024
The process of writing algorithms or pseudo codes before feeding them into program structures and executing them to get desired outputs is very magical indeed...
Formats: PDF, Epub, Kindle, TXT

Reads:
222
Pages:
21
Published:
Jun 2023
Unlock the Power of Windows with Basic Keyboard Shortcut Keys for XP, 7, 8, 10, and 11. This comprehensive guide provides a curated list of essential keyboard...
Formats: PDF, Epub, Kindle, TXT

Reads:
297
Pages:
59
Published:
Jan 2022
Thanks to advances in technology and new ways that employees interact and meet with one another, virtual networking now makes it possible to reach others and ...
Formats: PDF, Epub, Kindle, TXT

Reads:
108
Pages:
170
Published:
Nov 2020
This is an advanced and completely descriptive book for the continuous Bernoulli distribution that is very important to deep learning and variational autoenco...
Formats: PDF