Voici la syntaxe générale de création d’un index, que celui-ci soit ordonné ou non :
CREATE [UNIQUE] [CLUSTERED | NONCLUSTERED] INDEX Nom_Index
ON Nom_Table (Nom_Colonnes1)
[INCLUDE (Nom_Colonnes2)]
[WITH]
[PAD_INDEX OFF], [FILLFACTOR = x],
[IGNORE_DUP_KEY = OFF], [DROP_EXISTING OFF],
[ONLINE = OFF], [STATISTICS_NORECOMPUTE = OFF]
[ON Nom_Groupe_Fichier]
Pour créer un index, nous nous servons de l’instruction CREATE INDEX. Les choix compris
entre les mots clés CREATE et INDEX servent à décider si l’index doit être ordonné ou non,
et s’il doit être unique. Avec la clause ON, on définit sur quelles colonnes porte l’index et avec
la clause INCLUDE, on passe en paramètres plus de colonnes de la même table, afin que les
requêtes n’aient qu’à chercher dans l’index lorsqu’elles s’exécutent. La clause ON en toute fin
de lot permet de définir sur quel groupe de fichier nous allons placer notre index. On peut
noter que si le groupe de fichier n’est pas précisé, l’index sera placé dans le groupe de fichier
principal. À la suite de la clause WITH, nous trouvons les différentes options des index, qui
par défaut sont toutes désactivées (OFF) mis à part FILLFACTOR. Voici le détail des services
que proposent ces options :
92
- PAD_INDEX : Précise le niveau de remplissage du niveau non-feuille. Cette option n’est
utilisable qu’avec FILLFACTOR dont la valeur est reprise.
- FILLFACTOR : Précise le pourcentage de remplissage des pages d’index au niveau feuille.
La valeur par défaut est 0.
- IGNORE_DUP_KEY : Cette option autorise les entrées doubles dans les index de type
UNIQUE.
- DROP_EXISTING : Précise que l’index existant doit être supprimé.
- ONLINE : Lorsque cette option est activée, les données de la table restent accessibles en
lecture, lors de la création de l’index.
- STATISTICS_NORECOMPUTE : désactivée, cette option précise que les statistiques ne
seront pas mises à jour.
Nous allons maintenant créer un index non ordonné sur notre base de données Entreprise,
base de données dont nous nous servons pour tous nos exemples dans ce cours. Cette base
est accessible en annexe. Prenons un exemple simple. Dans notre table Client de la base de
données Entreprise, le mail des clients peut être à la valeur NULL. De plus, on remarque que
le champ Mail_Client n’est occupé que pour 50% des cas, soit un cas sur deux. L’accès aux
données est donc ralenti par le fait que la plupart des données sont à NULL. On peut donc
créer un index non organisé de cette manière :
CREATE NONCLUSTERED INDEX Index_Mail
ON Client (Mail_Client)
INCLUDE (Id_Client)
WHERE Mail_Client IS NOT NULL
Avec ce segment de code, nous allons créer un index non organisé, qui s’appelle Index_Mail,
sur la table Client, pour la colonne Mail_Client, à laquelle nous incluons Id_Client. Cet index
va récupérer toutes les informations de la table Client pour laquelle Mail_Client n’est pas
NULL, ce qui va nous permettre d’accélérer nos requêtes de façon conséquente, dans le cas
où la masse de données sur la base est conséquente.
Un index est automatiquement créé lorsqu’une contrainte PRIMARY KEY ou UNIQUE est
ajoutée à une table.
Dans la plupart des cas, il est préférable d’utiliser la contrainte UNIQUE plutôt qu’un index
unique. L’instruction CREATE INDEX échouera s’il existe des doublons dans la colonne à
indexer.
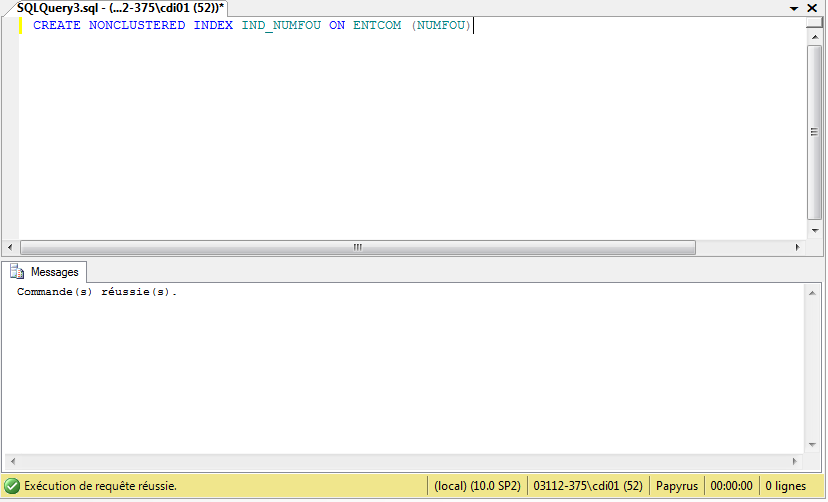
Pour revenir à notre exemple de départ « Créez un index non-cluster sur la colonne NUMFOU
de la table ENTCOM », nous faisons simplement :
93