On peut définir une vue comme étant une table dite virtuelle, qui a la même utilisation qu’une
table, simplement une vue ne prend pas d’espace sur le disque, puisqu’elle ne stocke pas les
données comme une table. Elle ne stocke que la requête d’extraction des données (SELECT).
Les vues sont un grand avantage quant à la gestion des données, vis-à-vis de l’utilisateur
final. En effet, elles permettent tout d’abord de simplifier la structure des tables, qui peuvent
parfois comporter une multitude de colonnes. On pourra alors choisir, en fonction de
l’utilisateur, les colonnes dont il aura besoin, et n’inclure que ces colonnes dans notre vue.
Une vue peut aussi permettre la réutilisation des requêtes. En effet, lorsque certaines
requêtes sont souvent utilisées, une vue permettra de stocker cette requête et de l’utiliser
plus facilement.
Une vue partitionnée est définie par une opération UNION ALL portant sur des tables
membres structurées de façon identique, que ce soit sur une seule instance de SQL Server ou
dans un groupe d'instances autonomes SQL Server.
Pour un partitionnement local des données, la méthode recommandée consiste à recourir à
des tables partitionnées.
Si les tables d’une vue partitionnée se trouvent sur des serveurs différents, toutes les tables
impliquées dans la requête peuvent être analysées en parallèle, ce qui accroît les
performances pour cette requête.
Création d’une vue
Une vue permet de stocker une requête prédéfinie sous forme d’objet de base de données,
pour une utilisation ultérieure. Nous allons voir les deux possibilités existantes pour créer une
vue.
96
Avec l’interface
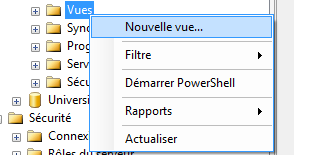
Il est très intuitif de créer une vue grâce à SSMS. Pour de faire, de manière graphique, il vous
suffit de cliquer droit sur le sous dossier « Vues » dans votre base de données, affichée dans
l’explorateur d’objet. Après avoir cliqué droit, sélectionnez « Nouvelle vue… »
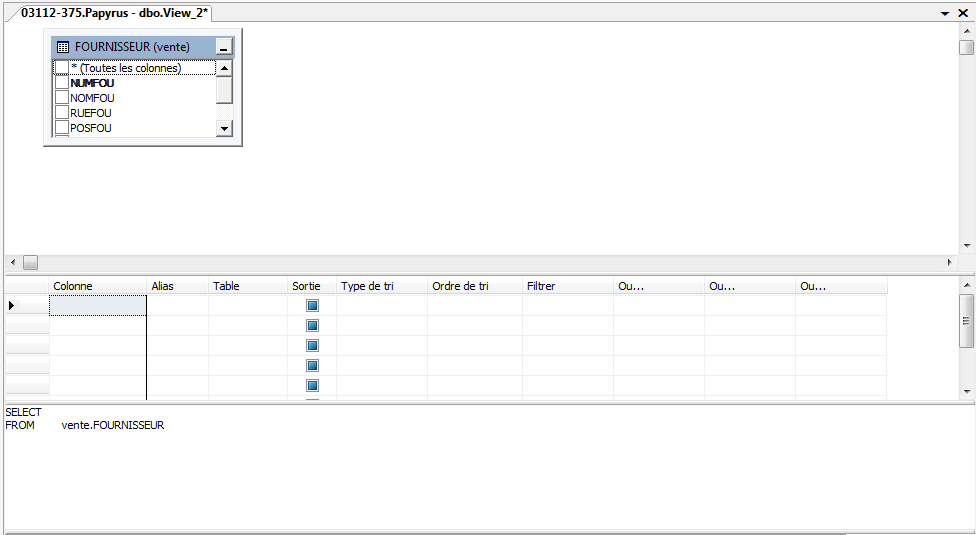
Après avoir cliqué sur « Nouvelle vue… », les deux fenêtres suivantes apparaissent au sein
même de SSMS. La première vous aidera à sélectionner des tables sur lesquelles la vue
portera. La seconde vous permet de sélectionner les colonnes à utiliser et construire votre
requête.
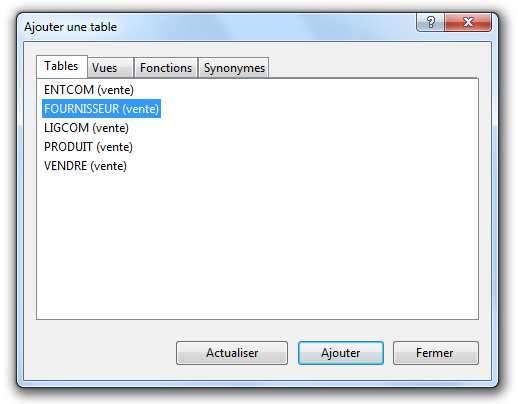
Pour ajouter une table, cliquez sur le nom de la table voulue, et sélectionnez « Ajouter ».
97
Vous pouvez en ajouter plusieurs par simple cliquez droit puis « Ajouter une table… ».
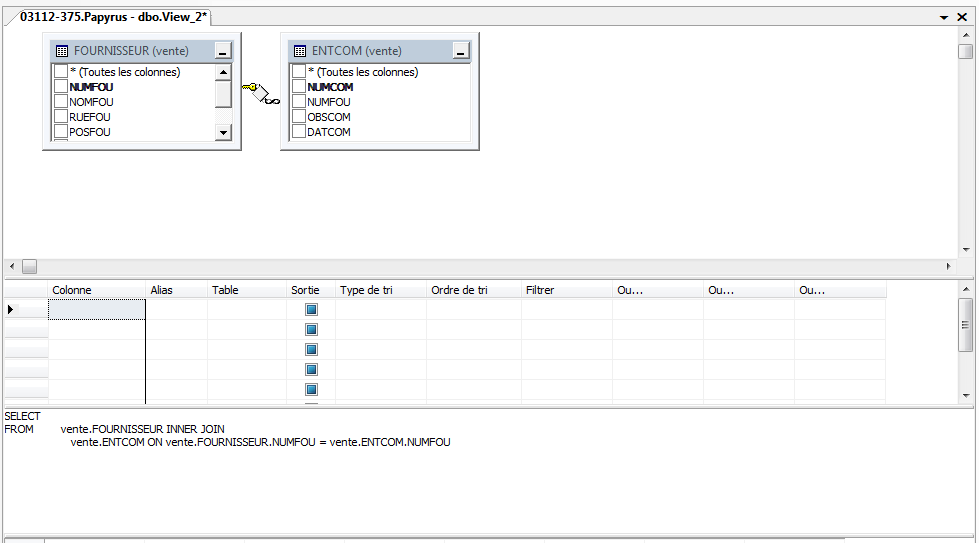
On remarquera que les tables, aussitôt sélectionnées, sont modélisées dans la partie
supérieure de la seconde fenêtre.
98

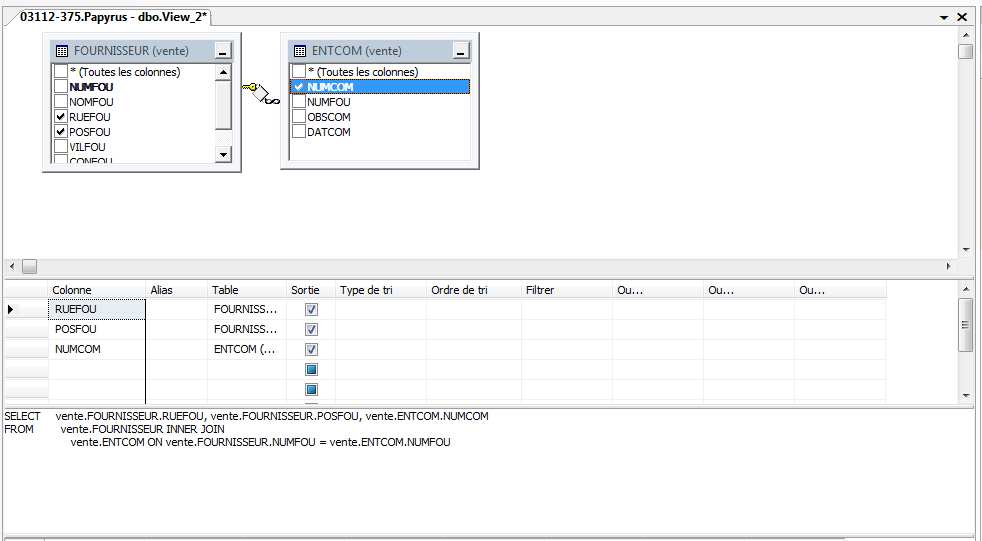
Pour sélectionner les colonnes à mettre dans votre vue, cochez les cases correspondant à vos
colonnes dans les tables modélisées dans la partie supérieure de la fenêtre. Lorsque l’on
coche des cases, on peut remarquer que le nom de ses colonnes est ajouté dans la partie
centrale de la fenêtre.
On peut alors modifier le type de tri, l’ordre, ou encore le filtre de cette vue en changeant les
caractéristiques dans la même partie. Toutes les actions effectuées permettront de générer le
code de la vue. Voici un exemple :
Lorsque vous avez fini de concevoir votre vue, faites cliquer droit sur l’onglet de la fenêtre
dans SSMS, et choisissez « Enregistrer ». Donnez-lui un nom. Vous venez de créer votre
vue.
Après actualisation, vous pourrez alors retrouver votre vue dans le sous-dossier de votre
explorateur d’objet, comme présenté dans l’image ci-dessous :
Création d’une vue avec du code T-SQL
La syntaxe de création d’une vue avec du code T-SQL est simple. On utilisera l’instruction
CREATE, comme pour toute création d’objets dans une base de données.
99
CREATE VIEW Nom_Vue
[options1]
AS requête [options2]
Nous utilisons l’instruction CREATE VIEW, auquel nous associons le nom que nous voulons
lui donner. Le mot clé AS indique que nous allons spécifier la requête SELECT qui va nous
permettre de sélectionner les colonnes d’une ou plusieurs tables, afin d’en copier les
propriétés dans la vue que nous créons. Il est bon de préciser que des clauses existantes pour
une instruction SELECT classique ne conviendra pas pour une instruction SELECT servant à
créer nos vues. Ces instructions ne doivent pas être autres que l’instruction SELECT, et les
clauses FROM et WHERE. Concernant les options 1 et 2 : L’option 1 correspond aux options
suivantes : WITH ENCRYPTION, WITH SCHEMABINDING, WITH VIEW_METADATA ; et
l’option 2 correspond à l’option suivant : WITH CHECK OPTION. Découvrons les actions de
chacune de ces options sur notre vue.
WITH ENCRYPTION : Permet de crypter le code dans les tables système. Attention :
personne ne peut consulter le code de la vue, même pas son créateur. Lors de la modification
de la vue avec l’instruction ALTER VIEW, il sera nécessaire de préciser de nouveau cette
option pour continuer à protéger le code de la vue.
WITH SCHEMABINDING : Permet de lier la vue au schéma. Avec cette option, il est
impératif de nommer nos objets de la façon suivante : schéma.objet.
WITH VIEW_METADATA : Permet de demander à SQL Server de renvoyer les métadonnées
correspondantes à la vue, et non celles qui composent la vue.
WITH CHECK OPTION : Permet de ne pas autoriser l’insertion ni la modification des
données ne correspondant pas aux critères de la requête.
Voici un exemple :
CREATE VIEW Ma_Premiere_Vue
WITH ENCRYPTION
AS SELECT Id_Client, Nom_Client
FROM dbo.Client
Cet exemple permet de créer une vue dont le nom est Ma_Première_Vue, avec l’option WITH
ENCRYPTION, et cette vue contiendra les colonnes Id_Client_archive et Id_Commande_
archive de la table Archive.
Exemple 1 : Créez la vue VentesI100 correspondant à la requête : « Afficher les ventes dont
le code produit est le I100 » (Affichage de toutes les colonnes de la table Vente)
-- VentesI100
CREATE VIEW VentesI100
-- Affichage de toutes les colonnes de la table Vente
AS SELECT *
-- Afficher les ventes (donc de la table Vente)
FROM vente.VENDRE
-- Où le code produit est I100
WHERE CODART = 'I100';
100
Exemple 2 : À partir de VentesI100, créer la vue VentesI100Grobrigan (toutes les ventes
concernant le produit I100 et le fournisseur 00120).
-- VentesI100Grobrigan
CREATE VIEW VentesI100Grobrigan
AS SELECT *
FROM VentesI100
WHERE NUMFOU = 00120;
Suppression d’une vue
Pour supprimer une vue, nous pouvons le faire via l’interface ou par le code.
Suppression d’une avec l’interface
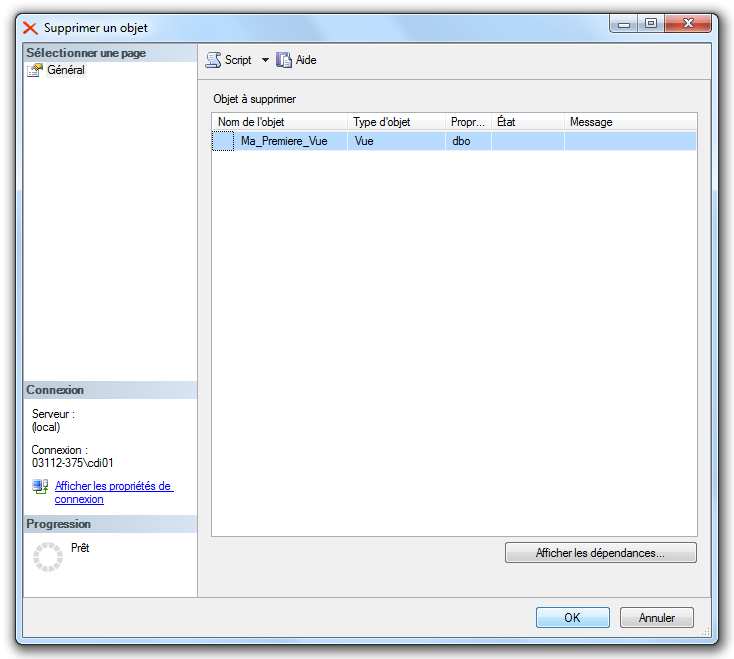
Avec SSMS, il vous suffit de cliquer droit sur la vue dans l’explorateur d’objet et de
sélectionner « Supprimer » et de cliquer sur « Ok » dans la nouvelle fenêtre qui apparaît.
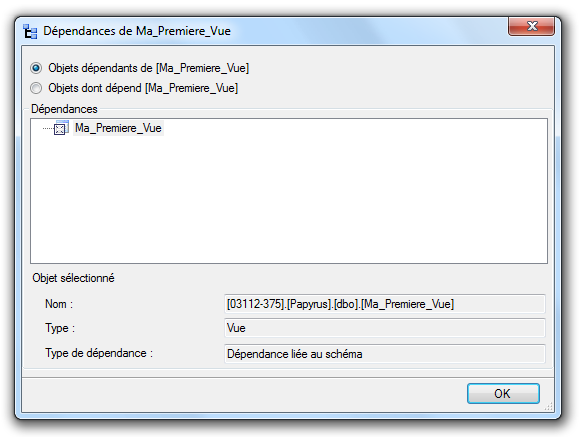
Grâce au bouton, « Afficher les Dépendances… », Il est possible de mettre en évidence les
dépendances existantes entre les objets de la base et la vue sélectionnée. Une nouvelle
fenêtre s’affiche à l’écran, dans laquelle vous pourrez choisir les différents types de
dépendances.
101
Il vous suffit juste de savoir si vous voulez afficher les objets dépendants de la vue ou ceux
dont dépend la vue en question.
Avec du code T-SQL
La structure de suppression d’une vue est la même que pour tout objet de la base de
données. Elle est la suivante :
DROP VIEW nom_vue
Les vues indexées
Les vues indexées ont un unique objectif, comme tout autre objet indexé dans la base de
données : améliorer les performances de nos requêtes. Celles-ci sont sûrement les objets de
la base offrant le plus de gain de performance dans SQL Server. On se sert le plus souvent de
ce type de vues, sur des bases de données OLAP, c'est-à-dire pour des données qui vont être
le plus souvent en lecture, et très peu mises à jour. Ces index sont en particulier pratiques
pour des requêtes nécessitant des jointures et des agrégations. La vue indexée a pour effet
de matérialiser les données. On prend le résultat de la requête et on le stocke dans l’index.
On met ensuite à jour l’index en fonction des modifications sur la table de base. La création
d’un index sur une vue se fait de la même manière que pour une table, simplement, un index
sur une vue présente de caractères propres de fonctionnement et de comportement que nous
avons commencé à présenter. Pour une version Entreprise de SQL Server, dès lors que votre
index est créé, le moteur de base de données utilisera celui-ci. En revanche, pour les autres
versions de SQL Server, il faut préciser si l’on veut utiliser l’index. La méthode est :
SELECT * FROM vue_Client WITH(NOEXPAND)
102
La clause WITH(NOEXPAND) spécifie qu’aucune vue indexée n’est étendue pour permettre
d’accéder aux tables sous-jacentes lorsque l’optimiseur de requête traite la requête.
L’optimiseur de requête traite la vue comme une table avec un index cluster. NOEXPAND
s’applique uniquement aux vues indexées. Des contraintes sont à noter. En effet, il n’est
possible de créer un index sur une vue que si les conditions suivantes sont rassemblées :
- Lors de la création de la vue, les options ANSI_NULLS et QUOTED IDENTIFIER doivent
être sur ON.
- ANSI_NULL doit être ON lors de la création de toutes les tables référencées dans la vue
sur laquelle sera créé l’index.
- La vue ne doit pas faire référence à d’autres vues.
- Toutes les tables référencées doivent appartenir à la même base et au même propriétaire.
- La vue doit être créée avec l’option WITH SCHEMABINDING.
Le premier index créé sur une vue doit être de type cluster unique. Par la suite il est possible
de construire des index non cluster.
Pour faire un résumé rapide, les vues indexées sont pratiques et efficaces dans le cas où une
vue possède une quantité remarquable de jointures et d’agrégations, et que ces données sont
surtout en lecture sur la base. Enfin, pour une création sans erreurs de l’index, certaines
conditions doivent être respectées.
Des index peuvent être créés sur des vues. Une vue indexée stocke l’ensemble des résultats
d’une vue dans la base de données. En raison de leur faible temps d’extraction, les vues
indexées peuvent être utilisées pour améliorer les performances d’une requête.
Une vue indexée est créée en implémentant un index UNIQUE CLUSTERED sur la vue.
D’autres index peuvent être créés.
Une vie indexée renvoie les modifications effectuées sur les données dans les tables de base.
L’index UNIQUE CLUSTERED est mis à jour à mesure que les données sont modifiées.
Une vue peut être modifiée par ALTER VIEW, et supprimée par DROP VIEW.
Gestion des schémas
Un schéma est un ensemble logique d’objets à l’intérieur des bases de données sur le serveur.
Leur but est de faciliter, entre autres, l’échange de données entre les utilisateurs, sans pour
autant affecter la sécurité. Concrètement, les schémas permettent une gestion plus aisée des
privilèges d’utilisation des objets. Comme nous l’avons vu précédemment, un utilisateur est
mappé sur un schéma dès sa création, obligatoirement. Si toutefois, aucun nom de schéma
n’est précisé, alors l’utilisateur sera mappé sur dbo par défaut. Pour expliquer simplement le
fonctionnement des schémas, prenons un exemple : un utilisateur est mappé sur un schéma
nommé RU. Pour requêter sur les objets de la base, il pourra écrire directement le nom seul
de cet objet si celui-ci est compris dans le schéma sur lequel il est mappé. Dans le cas
contraire, l’utilisateur devra préciser le schéma de l’objet, le nom de l’objet et à ce moment-
là, SQL Server cherchera si ledit utilisateur possède les droits d’utiliser l’objet auquel il tente
d’accéder. On peut retenir que les schémas servent essentiellement à faciliter le partage
d’information entre les utilisateurs mappés sur ce schéma.
103
Créer un schéma
Vous pouvez créer un schéma directement à partir de l’interface où simplement à partir du
code.
Avec l’interface
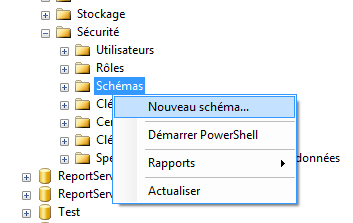
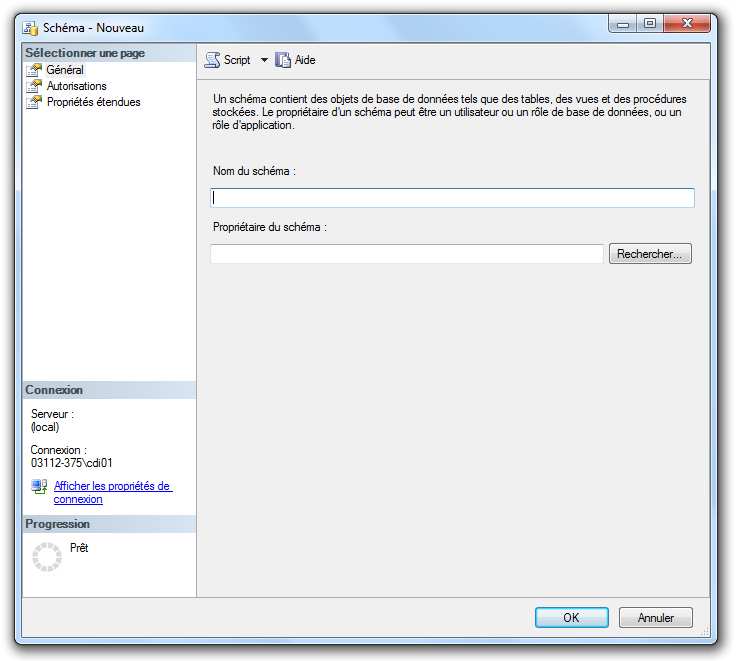
Pour créer un schéma grâce à SSMS, il vous suffit de déployer tous les nœuds jusqu’à
sécurité, d’afficher le menu contextuel (cliquez droit) du nœud schéma et de sélectionner
« Nouveau schéma ». Une nouvelle fenêtre apparaît.
Donnez un nom à votre schéma et configurez à votre guise.
Avec du code T-SQL
Voici la syntaxe de création d’un schéma de base de données :
CREATE SCHEMA nomschema
104
AUTHORIZATION nomproprietaire
options
Pour créer un schéma de base de données, nous nous servons de l’instruction CREATE
SCHEMA. Comme tout objet dans une base de données, un schéma doit avoir un nom unique
dans la famille des schémas. Il est donc nécessaire de préciser un nom derrière cette
instruction. La clause instruction va nous permettre en revanche de préciser l’utilisateur de
base de données qui sera propriétaire du schéma. Pour finir, ce que nous avons représenté
par option représente l’espace dans lequel nous pouvons directement faire la définition de nos
tables, vues et privilèges rattachés à nos tables.
Ici nous créons un schéma vente.
CREATE SCHEMA vente
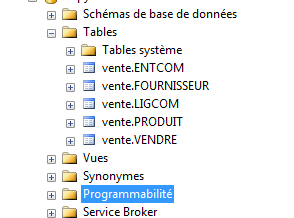
Nous appliquons ce schéma vente au tables suivantes :
ALTER SCHEMA vente TRANSFER dbo.ENTCOM
ALTER SCHEMA vente TRANSFER dbo.FOURNISSEUR
ALTER SCHEMA vente TRANSFER dbo.LIGCOM
ALTER SCHEMA vente TRANSFER dbo.PRODUIT
ALTER SCHEMA vente TRANSFER dbo.VENDRE
Après actualisation :
Modification d’un schéma
Vous pouvez modifier un schéma directement à partir de l’interface où à partir du code T-SQL.
Avec l’interface
Avec l’interface graphique, la manipulation est la même que pour la création d’un schéma.
Cependant, il faudra veiller à ne pas créer un nouveau schéma, mais à se rendre dans les
propriétés du schéma que nous voulons modifier. Il faut en revanche prendre en compte que
l’on ne peut pas changer le nom du schéma, seulement les tables, vue qui y sont contenues,
les autorisations et le propriétaire du schéma.
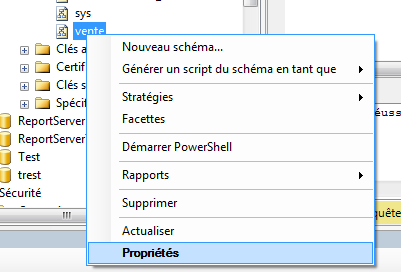
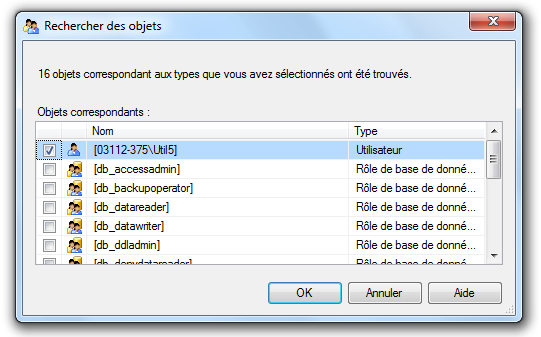
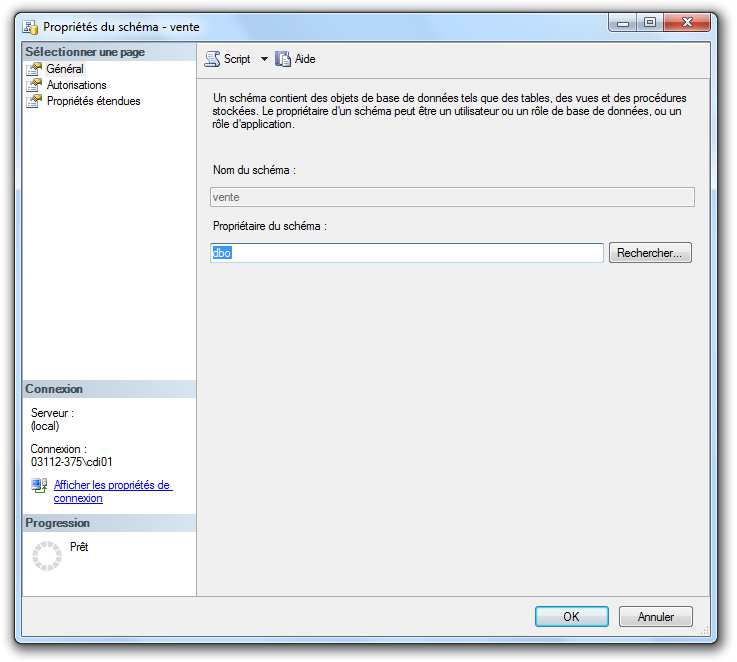
Par exemple, nous souhaitons désigner l’utilisateur « Util5 » comme propriétaire du schéma
vente : Cliquez droit sur le schéma vente puis « Propriétés ».
105
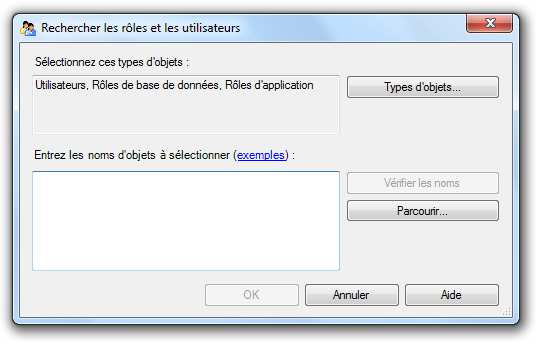
Cliquez sur « Rechercher… »
Puis cliquez sur « Parcourir ».
Sélectionnez l’utilisateur concerné puis cliquez sur « Ok ».
106
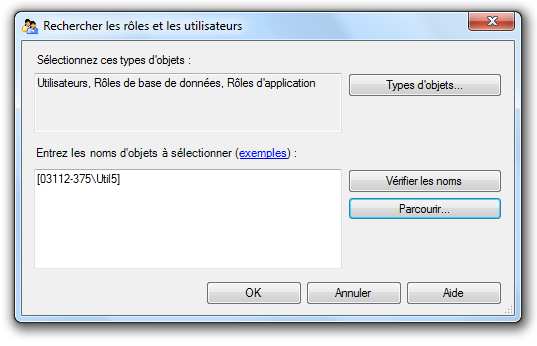
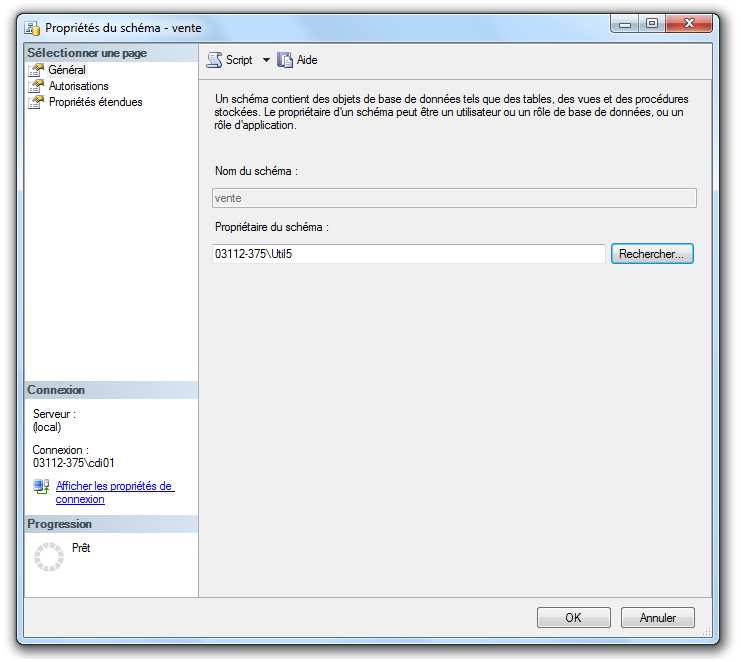
Cliquez de nouveau sur « Ok ».
« Util 5 » est maintenant propriétaire du schéma.
107