ReMaDDer Software Tutorial
How to use ReMaDDer software for successful records matching, data cleansing and data deduplication projects
ReMaDDer is record linkage and data cleansing software, with powerful fuzzy record matching and data deduplication capabilities, based on state of the art machine learning and data processing techniques.
As client-server application, ReMaDDer consists of two parts: client front-end part and server-side part. Client front-end provides user-friendly graphical interface with intuitive means for projects creation, raw data import and solutions definition, while server-side part ensures mighty data processing engine that can solve even the most complex fuzzy match analysis in reasonable time.
By combining advanced artificial intelligence with clever blocking techniques and multiple string similarity metrics, ReMaDDer provides unique solution for fully automatic records matching and data deduplication projects.
Traditionally, fuzzy records matching software require substantial human intervention, either to provide various parameters and threshold values, either to perform extensive clerical review and supervised machine learning training. Unique property of the ReMaDDer software is that it does not require any such human assistance beyond project definition. There are no thresholds or any other input parameters which user must provide in order to enable software to distinguish between matches and non-matches, the ReMaDDer software is capable to infer and learn everything by itself.
As far as we are aware, ReMaDDer might be the only software currently available that is capable to perform fully automatic fuzzy record matching without human expert intervention, while attaining accuracy of human clerical review. This is accomplished by utilizing various advanced machine learning techniques and approaches.
The name “ReMaDeDer” is an acronym for “Records Matching and Data Deduplication
Homepage: http://ReMaDDersoft.wix.com/ReMaDDer
Term “fuzzy match” refers to methods of identifying related records by measuring how similar they are. It is used in cases where no unique identifier or exact match relation exists between two sets of data.
Fuzzy matching uses weights to calculate the probability that two given records refer to the same entity. Record pairs with probabilities above a certain threshold are considered to be matches, while pairs with probabilities below threshold are considered to be non-matches.
Fuzzy matching attempts to find a match which, although not a 100 percent match, is above the threshold matching percentage set by the application.
Record linkage refers to the task of finding records in a data set that refer to the same entity across different data sources, i.e. to identify related records in two separate data sets.
Record linkage is necessary when joining data sets is based on entities that may or may not share a common identifier, as may be the case due to differences in record shape, storage location, and/or curator style or preference.
There are many business cases where record linkage has to be performed. Some typical examples are product price lists, partner lists, book and movie catalogs, customer loyalty databases, medical records etc.
Data deduplication refers to identifying duplicate records in a dataset and cleansing datasets from redundant information.
Due to its inherent complexity, fuzzy match analysis is a popular subject of scientific research and academic papers. Some of the researchers even tend to build their own software, but those programs suffer from their complexity and necessity to understand advanced mathematics and algorithms, in order to be able to use it. This is not something that can be expected from an average user facing data linkage problem in urge to be able to solve it in matter of hours or days.
On the other hand, there are huge corporate entity resolution framework solutions, produced by big software companies, oriented towards huge corporate customers. These solutions are often very complex and affordable only to big companies and corporate users.
ReMaDDer places itself in the middle and provides powerful fuzzy match records linkage solution for mere mortals and regular office users.
By allowing users to define exact matching constraints, fuzzy matching constraints and all other constraints in visual and intuitive way, all the complexity of the fuzzy match analysis is hidden from the user and he/she can focus on the business case, rather than technical issues. That is where ReMaDDer software really shines and clearly distinguishes itself from competition.
Traditionally, fuzzy record matching software suffer from requiring immense user involvement in project parameterization and clerical review. User is either required to provide various input parameters and threshold values, either he/she is required to perform machine learning training and provide examples of matches and non-matches. In both cases, considerable user involvement and expertise is prerequisite for successful analysis.
On the contrary, the ReMaDDer software does not require such heavy user involvement, since it can figure optimal parameter values automatically, all by itself. This is accomplished by advanced artificial intelligence utilizing various state of the art machine learning techniques.
To summarize: utilization of advanced artificial intelligence, accompanied with intuitive graphical user interface and low pricing - that is what makes ReMaDDer superb fuzzy match records linkage solution.
Major prerequisite to use ReMaDDer is active internet connection, since the raw data is imported to remote server where data is processed. After trial period expires, you are required to purchase commercial release code in order to be able to continue using remote server.
However, project and solution creation and editing can be performed even without established connection and purchased release code, since these data are stored locally on your computer.
ReMaDDer front-end client is available as executable for Windows and Linux systems. It is possible to provide executables for various other systems, on demand.
ReMaDDer does not operate directly on original data sources, but requires data to be imported from CSV (comma separated values) flat files to server, where corresponding “left” and “right” database tables are then created and processed. Therefore, you will have to provide source datasets as flat CSV file, encoded in UTF-8, preferably with comma (“,”) or semi-colon (“;”) field separators.

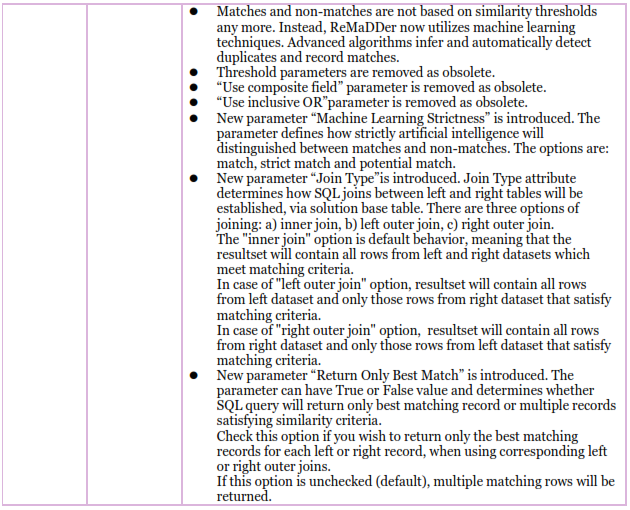
Project is basic entity in ReMaDDER software. Each project contains definition of two source datasets to be imported and analyzed (so-called "left dataset" and "right dataset"), as well as variable number of corresponding solutions, which are stored definitions of how to perform fuzzy match analysis.
On creation, each project is assigned unique project tag. During raw data importing to server, corresponding input tables get that tag appended in their name. This way, imported tables are always tagged by the project name, which ensures their uniqueness.
The “Projects” page consists of two two sections separated by movable splitter. In upper section there is a datagrid view where you can browse and edit projects, while on the lower section there is form view of currently selected project. The same concept of datagrids and form views is implemented throughout the application.
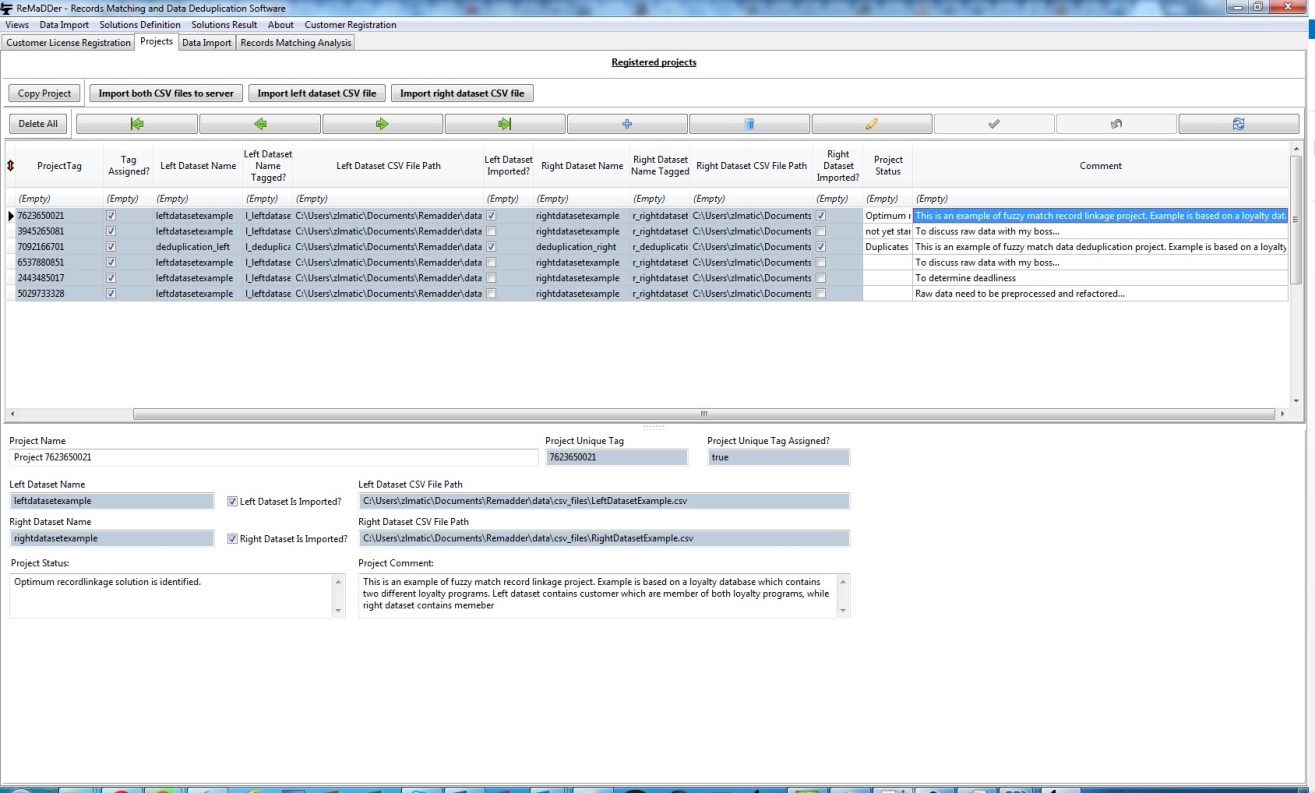
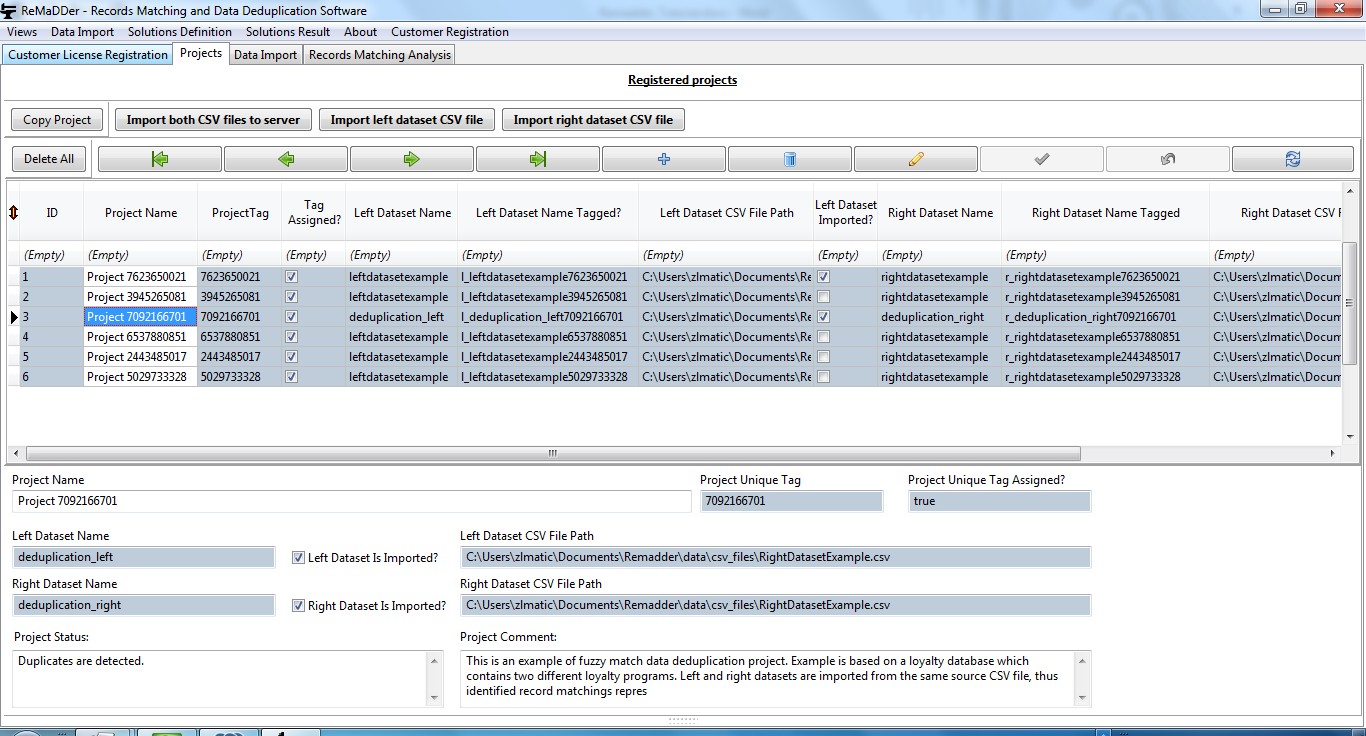
You can easily create new projects, edit and browse existing projects, by using navigator buttons.
![]()
Throughout ReMaDDer application and this manual, we will use terms “left” and “right” dataset or table.
In every fuzzy match project, we always compare two tables, i.e. two datasets, inspecting their rows similarity. For convenience, we call them “left” and “right” table.
Purpose of entity resolution framework software, such is ReMaDDer, is to identify which records from “left” dataset correspond to which records from “right” dataset.
ReMaDDer does not operate on original data sources directly, but requires data to be imported from source CSV (comma separated values) flat files to server, where corresponding left and right database tables are then created and processed.
In ReMaDDer software, there is no fundamental difference between data deduplication and records matching projects. In both cases we compare two datasets, trying to infer which records from “left” dataset correspond to which records in “right” dataset.
The only difference between the two is that in case of records matching project we have two different input datasets to be compared, while in case of data deduplication project we have to compare a dataset with itself, in order to identify duplicate records in the dataset.
Since ReMaDDer software always compare two datasets - left and right datasets, in case of data deduplication project we need to import the same original CSV file twice - first as left dataset and then as right dataset. The ReMaDDer software will thus create two identical tables with different names, in the underlying database.
Instead of manually entering all the parameters for new projects, ReMaDDer allows you to copy existing project into another project. This action copies raw data import specifications as well as solution definitions.
Datasets to be analyzed are called "left" and "right" datasets and can be easily imported from source CSV files, encoded in UTF-8.
The CSV file format ("Comma Separated Values") is chosen due to its ubiquity and because all databases and spreadsheet editors, as well as all other data sources can be easily exported to a csv file.
The source data CSV files, however, must be UTF-8 encoded. Otherwise, import will most likely fail. Therefore, you must first ensure that the source data CSV files are properly UTF-8 encoded. ReMaDDer has embedded tools for charset encoding detection and conversion, but you can also use famous Notepad++ (https://notepad-plus-plus.org/), CudaText (http://uvviewsoft.com/cudatext/) and other powerful text editors which are capable to perform encoding detection and conversion of files.
ReMaDDer provides simple and intuitive tool for importing csv files. It will automatically detect field’s delimiter and columns schema information. You can then edit the retrieved schema and finally import the files on server, for further processing.
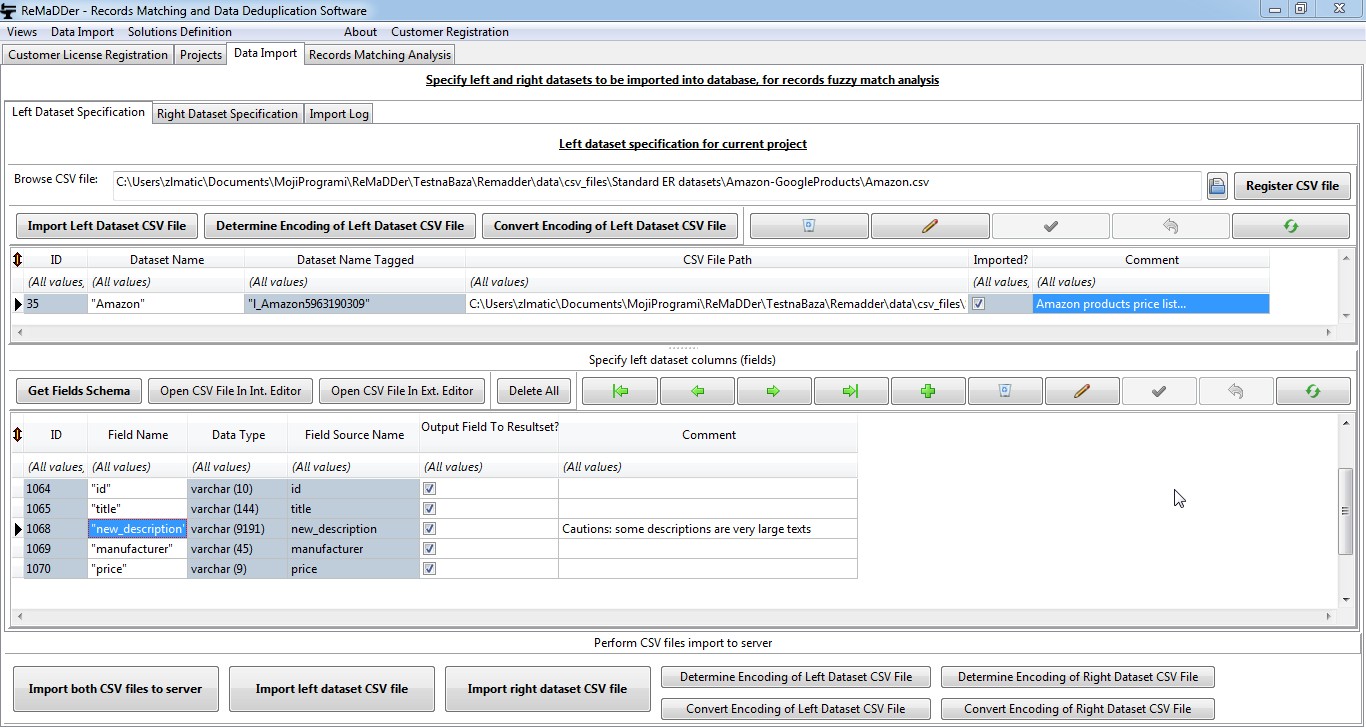
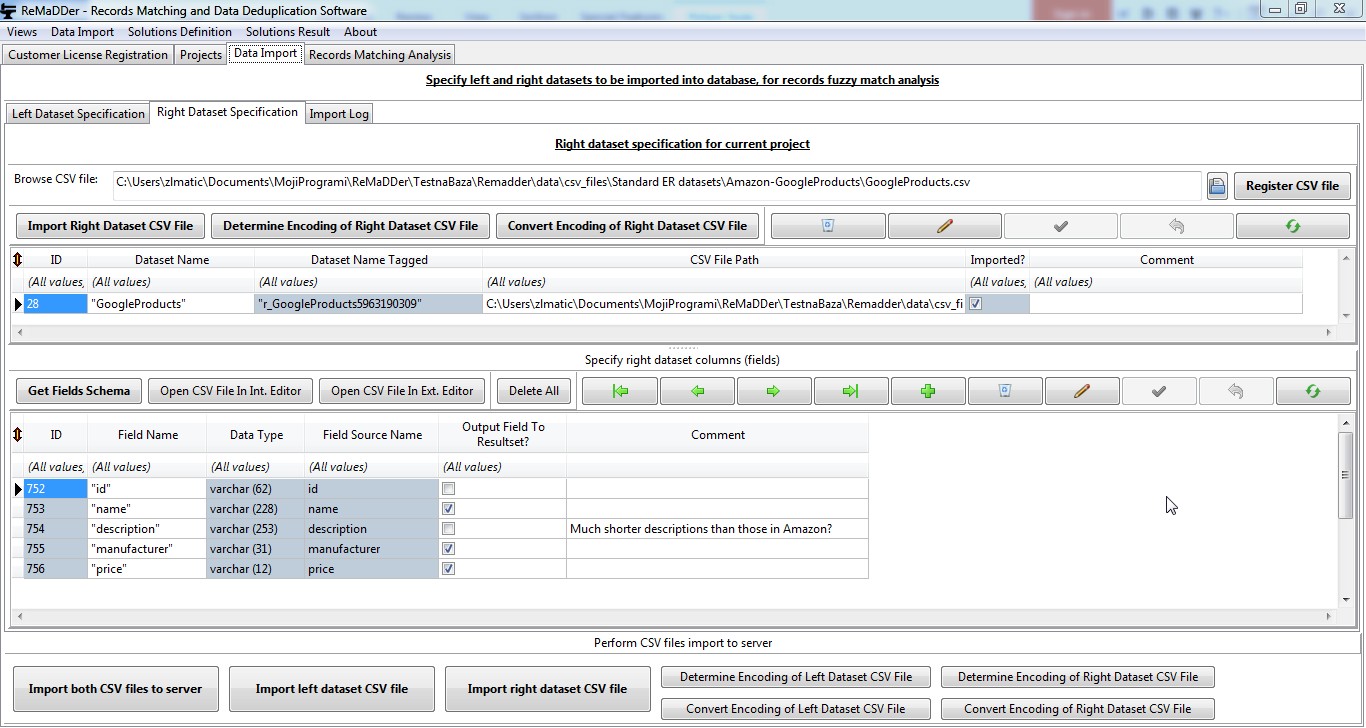
In each data deduplication or record matching project, we always compare two datasets for matching of records. In case of record matching projects, these two datasets correspond to two different input CSV files, while in case of data deduplication projects, these two datasets are imported from the same input CSV file.
Nevertheless, we always have so-called “left dataset” and “right dataset” to be compared. Think of this like comparing fingers from left and right hand. You can easily identify thumb on the left hand to be related to the thumb on the right hand, since they share similar shape. It is obvious due to their physical similarity.
It is same with fuzzy match analysis, where we compare fields from left and right dataset in order to identify string similarities. ReMaDDer internally uses various functions to measure string similarities, results of which are then processed by artificial intelligence to infer whether two records represent same entity or not.
Process of importing raw data into server database consists of several logical phases. First we need to identify source CSV files for “left” and “right” dataset. After source files are identified, we need to ensure that the CSV files are properly UTF-8 encoded. Once we ensured proper encoding, then we need to retrieve and specify schema information about the CSV files. In last phase we actually perform import from source files, according to previously defined schema. Result of the last step is that the source files are imported on server-side database, where they can be processed according to various solution definitions.
On “Data Import” page, there are two sub-pages: “Left Dataset Specification” and “Right Dataset Specification”, in which we separately define input dataset specifications for “left” and “right” dataset.
Import can be executed separately for left and righ dataset, or both can be imported in batch, at once.
First step in importing input CSV files is to choose CSV files to be imported.
On upper part of “Left Dataset Specification” or “Right Dataset Specification” sub-page, there is a CSV file browser dialog box.

You can browse CSV files on your computer by clicking on the browse button  . This opens a file browser in which you can choose a CSV file. The absolute file path is then copied to the edit box.
. This opens a file browser in which you can choose a CSV file. The absolute file path is then copied to the edit box.
![]()
Next step is to define CSV file schema specification. We call this process “registering CSV file”.

Reads:
127
Pages:
90
Published:
Sep 2023
I hope you enjoy this FREE ebook. Thanks for downloading it.
Formats: PDF, Epub, Kindle, TXT

Reads:
103
Pages:
74
Published:
Sep 2023
Databases are crucial for managing and utilising data effectively in various industries and applications. The aim of this book is to enable the reader to revi...
Formats: PDF, Epub, Kindle, TXT

Reads:
31
Pages:
293
Published:
Jul 2023
How-to's are step-by-step tutorials that are designed to help you learn more about Maya.
Formats: PDF, Epub, Kindle, TXT

Reads:
115
Pages:
176
Published:
Apr 2023
"No Filter, No Problem" by Famium is your ultimate guide to creating a visually stunning, engaging Instagram presence. Packed with insider secrets and practic...
Formats: PDF, Epub, Kindle, TXT