CHAPTER
A (SLIGHTLY) FASTER CPYTHON IMPLEMENTATION
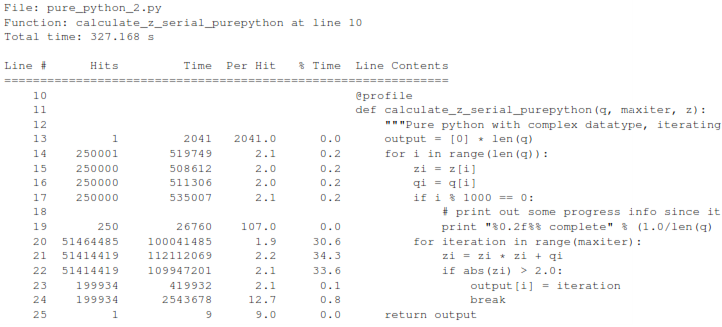
Having taken a look at bytecode, let’s make a small modification to the code. This modification is only necessary for CPython and PyPy - the C compiler options for us won’t need the modification.
All we’ll do is dereference the z[i] and q[i] calls once, rather than many times in the inner loops:
# \python\pure_python_2.py
for i in range(len(q)):
zi = z[i]
qi = q[i]
...
for iteration in range(maxiter):
zi = zi * zi + qi
if abs(zi) > 2.0:
Now look at the kernprof.py output on our modified pure_python_2.py. We have the same number of function calls but they’re quicker - the big change being the cost of 2.6 seconds dropping to 2.2 seconds for the z = z * z + q line. If you’re curious about how the change is reflected in the underlying bytecode then I urge that you try the dis module on your modified code.
Here’s the improved bytecode:
>>> dis.dis(calculate_z_serial_purepython)
...
22 129 LOAD_FAST 5 (zi)
132 LOAD_FAST 5 (zi)
135 BINARY_MULTIPLY
136 LOAD_FAST 6 (qi)
139 BINARY_ADD
140 STORE_FAST 5 (zi)
24 143 LOAD_GLOBAL 2 (abs)
146 LOAD_FAST 5 (zi)
149 CALL_FUNCTION 1
152 LOAD_CONST 6 (2.0)
155 COMPARE_OP 4 (>)
158 POP_JUMP_IF_FALSE 123
...
You can see that we don’t have to keep loading z and i, so we execute fewer instructions (so things run faster).