By the end of this chapter, the student should be able to:
Calculate and interpret confidence intervals for one population mean and one population proportion.
Interpret the student-t probability distribution as the sample size changes.
Discriminate between problems applying the normal and the student-t distributions.
Suppose you are trying to determine the mean rent of a two-bedroom apartment in your town. You might look in the classified section of the newspaper, write down several rents listed, and average them together. You would have obtained a point estimate of the true mean. If you are trying to determine the percent of times you make a basket when shooting a basketball, you might count the number of shots you make and divide that by the number of shots you attempted. In this case, you would have obtained a point estimate for the true proportion.
We use sample data to make generalizations about an unknown population. This part of statistics is called inferential statistics. The sample data help us to make an estimate of a population parameter. We realize that the point estimate is most likely not the exact value of the population parameter, but close to it. After calculating point estimates, we construct confidence intervals in which we believe the parameter lies.
In this chapter, you will learn to construct and interpret confidence intervals. You will also learn a new distribution, the Student's-t, and how it is used with these intervals. Throughout the chapter, it is important to keep in mind that the confidence interval is a random variable. It is the parameter that is fixed.
If you worked in the marketing department of an entertainment company, you
might be interested in the mean number of compact discs (CD's) a consumer
buys per month. If so, you could conduct a survey and calculate the sample
mean, 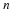 , and the sample standard deviation, s. You would use
, and the sample standard deviation, s. You would use 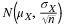 to estimate
the population mean and s to estimate the population standard deviation. The
sample mean,
to estimate
the population mean and s to estimate the population standard deviation. The
sample mean, 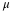 , is the point estimate for the population mean, μ. The sample
standard deviation, s, is the point estimate for the population standard deviation,
σ.
, is the point estimate for the population mean, μ. The sample
standard deviation, s, is the point estimate for the population standard deviation,
σ.
Each of 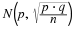 and
s is also called a statistic.
and
s is also called a statistic.
A confidence interval is another type of estimate but, instead of being just one number, it is an interval of numbers. The interval of numbers is a range of values calculated from a given set of sample data. The confidence interval is likely to include an unknown population parameter.
Suppose for the CD example we do not know the population mean μ but we do know that the population standard deviation is σ=1 and our sample size is 100. Then by the Central Limit Theorem, the standard deviation for the sample mean is
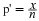 .
.
The Empirical Rule, which applies to bell-shaped distributions, says that in
approximately 95% of the samples, the sample mean, 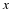 , will be within two standard
deviations of the population mean μ. For our CD example, two standard deviations
is (2)(0.1) = 0.2. The sample mean
, will be within two standard
deviations of the population mean μ. For our CD example, two standard deviations
is (2)(0.1) = 0.2. The sample mean 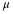 is likely to be within 0.2 units of μ.
is likely to be within 0.2 units of μ.
Because 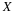 is within 0.2 units of μ, which is unknown, then μ is likely to be within 0.2 units
of
is within 0.2 units of μ, which is unknown, then μ is likely to be within 0.2 units
of 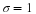 in 95% of the samples. The population mean μ is contained in an interval
whose lower number is calculated by taking the sample mean and subtracting
two standard deviations ((2)(0.1)) and whose upper number is calculated by
taking the sample mean and adding two standard deviations. In other words, μ
is between
in 95% of the samples. The population mean μ is contained in an interval
whose lower number is calculated by taking the sample mean and subtracting
two standard deviations ((2)(0.1)) and whose upper number is calculated by
taking the sample mean and adding two standard deviations. In other words, μ
is between 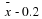 and
and
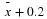 in 95% of all the samples.
in 95% of all the samples.
For the CD example, suppose that a sample produced a sample mean 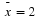 . Then the
unknown population mean μ is between
. Then the
unknown population mean μ is between
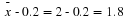 and
and
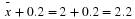
We say that we are 95% confident that the unknown population mean number of CDs is between 1.8 and 2.2. The 95% confidence interval is (1.8, 2.2).
The 95% confidence interval implies two possibilities. Either the interval (1.8, 2.2)
contains the true mean μ or our sample produced an 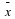 that is not within 0.2 units of
the true mean μ. The second possibility happens for only 5% of all the samples
(100% - 95%).
that is not within 0.2 units of
the true mean μ. The second possibility happens for only 5% of all the samples
(100% - 95%).
Remember that a confidence interval is created for an unknown population parameter like the population mean, μ. Confidence intervals for some parameters have the form
(point estimate - margin of error, point estimate + margin of error)
The margin of error depends on the confidence level or percentage of confidence.
When you read newspapers and journals, some reports will use the phrase "margin of error." Other reports will not use that phrase, but include a confidence interval as the point estimate + or - the margin of error. These are two ways of expressing the same concept.
Although the text only covers symmetric confidence intervals, there are non-symmetric confidence intervals (for example, a confidence interval for the standard deviation).
Have your instructor record the number of meals each student in your class eats out in a week. Assume that the standard deviation is known to be 3 meals. Construct an approximate 95% confidence interval for the true mean number of meals students eat out each week.
Calculate the sample mean.
σ = 3 and n = the number of students surveyed.
Construct the interval
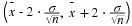
We say we are approximately 95% confident that the true average number of meals that students eat out in a week is between __________ and ___________.
Confidence Intervals: Confidence Interval, Single Population Mean, Population Standard Deviation Known, Normal is part of the collection col10555 written by Barbara Illowsky and Susan Dean with contributions from Roberta Bloom.
To construct a confidence interval for a single unknown population mean μ
, where
the population standard deviation is known, we need 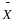 as an estimate for μ and we need the
margin of error. Here, the margin of error is called the error bound for a
population mean (abbreviated EBM). The sample mean
as an estimate for μ and we need the
margin of error. Here, the margin of error is called the error bound for a
population mean (abbreviated EBM). The sample mean 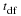 is the point estimate of the unknown population mean μ
is the point estimate of the unknown population mean μ
(point estimate - error bound, point estimate + error bound) or, in symbols,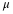 |
The margin of error depends on the confidence level (abbreviated CL). The confidence level is often considered the probability that the calculated confidence interval estimate will contain the true population parameter. However, it is more accurate to state that the confidence level is the percent of confidence intervals that contain the true population parameter when repeated samples are taken. Most often, it is the choice of the person constructing the confidence interval to choose a confidence level of 90% or higher because that person wants to be reasonably certain of his or her conclusions.
There is another probability called alpha ( α). α is related to the confidence level CL. α is the probability that the interval does not contain the unknown population parameter.
Mathematically, α + CL = 1.
| Suppose we have collected data from a sample. We know the sample mean but we do not know the mean for the entire population. |
| The sample mean is 7 and the error bound for the mean is 2.5. |
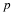 7 and
EBM
=
2.5.
7 and
EBM
=
2.5.
The confidence interval is ( 7 – 2.5 , 7 + 2.5 ) ; calculating the values gives ( 4.5 , 9.5 ) .
If the confidence level (CL) is 95%, then we say that "We estimate with 95% confidence that the true value of the population mean is between 4.5 and 9.5."
A confidence interval for a population mean with a known standard deviation is
based on the fact that the sample means follow an approximately normal
distribution. Suppose that our sample has a mean of 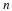 and we have constructed the 90% confidence interval (5, 15)
where
EBM
=
5
.
and we have constructed the 90% confidence interval (5, 15)
where
EBM
=
5
.
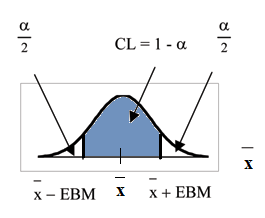
To get a 90% confidence interval, we must include the central 90% of the probability of the normal distribution. If we include the central 90%, we leave out a total of α = 10% in both tails, or 5% in each tail, of the normal distribution.
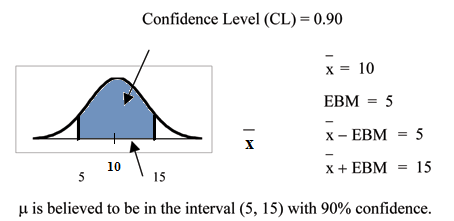
To capture the central 90%, we must go out 1.645 "standard deviations" on either side of the calculated sample mean. 1.645 is the z-score from a Standard Normal probability distribution that puts an area of 0.90 in the center, an area of 0.05 in the far left tail, and an area of 0.05 in the far right tail.
It is important that the "standard deviation" used must be appropriate for the parameter we are estimating. So in this section, we need to use the standard deviation that applies to sample means, which is
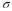 .
is commonly called the "standard error of the mean" in order to clearly distinguish the standard deviation for a mean from the population standard deviation σ .
.
is commonly called the "standard error of the mean" in order to clearly distinguish the standard deviation for a mean from the population standard deviation σ .
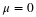 is normally distributed, that is,
~
is normally distributed, that is,
~
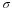
When the population standard deviation σ is known, we use a Normal distribution to calculate the error bound.
To construct a confidence interval estimate for an unknown population mean, we need data from a random sample. The steps to construct and interpret the confidence interval are:
Calculate the sample mean 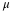 from the sample data. Remember, in this section, we already know the population standard deviation σ .
from the sample data. Remember, in this section, we already know the population standard deviation σ .
Find the Z-score that corresponds to the confidence level.
Calculate the error bound EBM
Construct the confidence interval
Write a sentence that interprets the estimate in the context of the situation in the problem. (Explain what the confidence interval means, in the words of the problem.)
We will first examine each step in more detail, and then illustrate the process with some examples.
When we know the population standard deviation σ, we use a standard normal distribution to calculate the error bound EBM and construct the confidence interval. We need to find the value of z that puts an area equal to the confidence level (in decimal form) in the middle of the standard normal distribution Z~N(0,1).
The confidence level, CL, is
the area in the middle of the standard normal distribution.
CL
=
1
–
α
.
So α is the area that is split equally between the two tails. Each of the tails contains an area
equal to
.
The z-score that has an area to the right of is denoted by 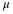
For example, when
CL
=
0.95 then
α
=
0.05 and 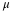 ;
we write
;
we write
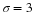
The area to the right of z.025 is 0.025 and the area to the left of z.025 is 1-0.025 = 0.975
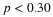 , using a calculator, computer or a Standard Normal probability table.
, using a calculator, computer or a Standard Normal probability table.
Using the TI83, TI83+ or TI84+ calculator:
invNorm(0.975,0,1)=1.96
CALCULATOR NOTE: Remember to use area to the LEFT of
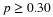 ; in this chapter the last two inputs in the invNorm command are 0,1 because you are using a Standard Normal Distribution Z~N(0,1)
; in this chapter the last two inputs in the invNorm command are 0,1 because you are using a Standard Normal Distribution Z~N(0,1)
The error bound formula for an unknown population mean μ when the population standard deviation σ is known is
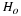
The confidence interval estimate has the format
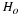 .
.
The graph gives a picture of the entire situation.
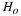 .
.
The interpretation should clearly state the confidence level (CL), explain what population parameter is being estimated (here, a population mean), and should state the confidence interval (both endpoints). "We estimate with ___% confidence that the true population mean (include context of the problem) is between ___ and ___ (include appropriate units)."
Suppose scores on exams in statistics are normally distributed with an unknown population mean and a population standard deviation of 3 points. A random sample of 36 scores is taken and gives a sample mean (sample mean score) of 68. Find a confidence interval estimate for the population mean exam score (the mean score on all exams).
Find a
90% confidence interval for the true (population) mean of statistics exam scores.
You can use technology to directly calculate the confidence interval
The first solution is shown step-by-step (Solution A).
The second solution uses the TI-83, 83+ and 84+ calculators (Solution B).
To find the confidence interval, you need the sample mean,
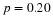 , and the EBM.
, and the EBM.
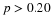 |
|
|
|