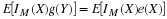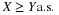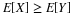In the treatment of the mathematical expection of a real random variable X, we note that the
mean value locates the center of the probability mass distribution induced by X on the
real line. In this unit, we examine how expectation may be used for further characterization
of the distribution for X. In particular, we deal with the concept of
variance and its square root the standard deviation. In subsequent units, we show
how it may be used to characterize the distribution for a pair  considered jointly with
the concepts covariance, and linear regression
considered jointly with
the concepts covariance, and linear regression
Location of the center of mass for a distribution is important, but provides limited information. Two markedly different random variables may have the same mean value. It would be helpful to have a measure of the spread of the probability mass about the mean. Among the possibilities, the variance and its square root, the standard deviation, have been found particularly useful.
Definition. The variance of a random variable X is the mean square of its variation about the mean value:
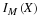
The standard deviation for X is the positive square root σX of the variance.
If X(ω) is the observed value of X, its variation from the mean is X(ω)–μX. The variance is the probability weighted average of the square of these variations.
The square of the error treats positive and negative variations alike, and it weights large variations more heavily than smaller ones.
As in the case of mean value, the variance is a property of the distribution, rather than of the random variable.
We show below that the standard deviation is a “natural” measure of the variation from the mean.
In the treatment of mathematical expectation, we show that
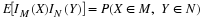
This shows that the mean value is the constant which best approximates the random variable, in the mean square sense.
Basic patterns for variance
Since variance is the expectation of a function of the random variable X, we utilize
properties of expectation in computations. In addition, we find it expedient to identify
several patterns for variance which are frequently useful in performing calculations. For one
thing, while the variance is defined as 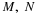 , this is usually not the most
convenient form for computation. The result quoted above gives an alternate expression.
, this is usually not the most
convenient form for computation. The result quoted above gives an alternate expression.
(V1): Calculating formula. 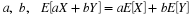 . .
|
(V2): Shift property. 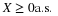 .
Adding a constant b to X shifts the distribution (hence its center of mass)
by that amount. The variation of the shifted distribution about the shifted center
of mass is the same as the variation of the original, unshifted distribution
about the original center of mass. .
Adding a constant b to X shifts the distribution (hence its center of mass)
by that amount. The variation of the shifted distribution about the shifted center
of mass is the same as the variation of the original, unshifted distribution
about the original center of mass.
|
(V3): Change of scale.  .
Multiplication of X by constant a changes the scale by a factor |a|. The squares
of the variations are multiplied by a2. So also is the mean of the squares of
the variations. .
Multiplication of X by constant a changes the scale by a factor |a|. The squares
of the variations are multiplied by a2. So also is the mean of the squares of
the variations.
|
(V4): Linear combinations
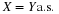 is the covariance of the pair is the covariance of the pair  , whose
role we study in the unit on that topic. If the cij are all zero, we say the class is
uncorrelated. , whose
role we study in the unit on that topic. If the cij are all zero, we say the class is
uncorrelated.
|
Remarks
If the pair 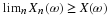 is independent, it is uncorrelated. The converse is not true, as
examples in the next section show.
is independent, it is uncorrelated. The converse is not true, as
examples in the next section show.
If the ai=±1 and all pairs are uncorrelated, then
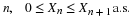
The variance add even if the coefficients are negative.
We calculate variances for some common distributions. Some details are omitted—usually details of algebraic manipulation or the straightforward evaluation of integrals. In some cases we use well known sums of infinite series or values of definite integrals. A number of pertinent facts are summarized in Appendix B. Some Mathematical Aids. The results below are included in the table in Appendix C.
Variances of some discrete distributions
Indicator function X = IEP ( E ) = p , q = 1 – p E [ X ] = p

Simple random variable (primitive
form)
(primitive
form) 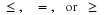 .
.
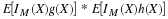
Binomial(n,p). 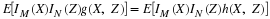
Geometric(p). P(X=k)=pqk∀k≥0E[X]=q/p
We use a trick: 
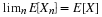
Poisson(μ)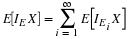
Using 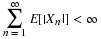 , we have
, we have
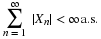
Thus, Var [X]=μ2+μ–μ2=μ. Note that both the mean and the variance have common value μ.
Some absolutely continuous distributions
Uniform on (a,b)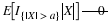

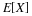
Symmetric triangular(a,b) Because of the shift property (V2), we may center the distribution at the origin. Then the distribution is symmetric triangular (–c,c), where c=(b–a)/2. Because of the symmetry
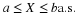
Now, in this case,
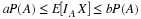
Exponential ( λ ) fX ( t ) = λ e – λ t , t ≥ 0 E [ X ] = 1 / λ
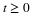
Gamma(α,λ)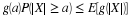
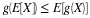
Hence 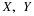 .
.
Normal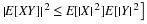 E[X]=μ
E[X]=μ
Consider 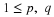 .
.
Extensions of some previous examples
In the unit on expectations, we calculate the mean for a variety of cases. We revisit some of those examples and calculate the variances.
A bettor places three bets at $2.00 each. The first pays $10.00 with probability 0.15, the second $8.00 with probability 0.20, and the third $20.00 with probability 0.10.
SOLUTION
The net gain may be expressed
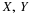
We may reasonbly suppose the class 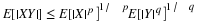 is independent (this assumption is not
necessary in computing the mean). Then
is independent (this assumption is not
necessary in computing the mean). Then
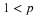
Calculation is straightforward. We may use MATLAB to perform the arithmetic.
c = [10 8 20]; p = 0.01*[15 20 10]; q = 1 - p; VX = sum(c.^2.*p.*q) VX = 58.9900
Suppose X in a primitive form is
with probabilities 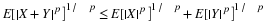 .
.
Let g(t)=t2+2t. Determine E[g(X)] and 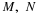
c = [-3 -1 2 -3 4 -1 1 2 3 2]; % Original coefficients pc = 0.01*[8 11 6 13 5 8 12 7 14 16]; % Probabilities for C_j G = c.^2 + 2*c % g(c_j) EG = G*pc' % Direct calculation E[g(X)] EG = 6.4200 VG = (G.^2)*pc' - EG^2 % Direct calculation Var[g(X)] VG = 40.8036 [Z,PZ] = csort(G,pc); % Distribution for Z = g(X) EZ = Z*PZ' % E[Z] EZ = 6.4200 VZ = (Z.^2)*PZ' - EZ^2 % Var[Z] VZ = 40.8036
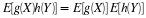 (Example 10 from "Mathematical Expectation: Simple Random Variables")
(Example 10 from "Mathematical Expectation: Simple Random Variables") We use the same joint distribution as for Example 10 from "Mathematical Expectation: Simple Random Variables" and let 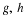 .
To set up for calculations, we use jcalc.
.
To set up for calculations, we use jcalc.
jdemo1 % Call for data jcalc % Set up Enter JOINT PROBABILITIES (as on the plane) P Enter row matrix of VALUES of X X Enter row matrix of VALUES of Y Y Use array operations on matrices X, Y, PX, PY, t, u, and P G = t.^2 + 2*t.*u - 3*u; % Calculation of matrix of [g(t_i, u_j)] EG = total(G.*P) % Direct calculation of E[g(X,Y)] EG = 3.2529 VG = total(G.^2.*P) - EG^2 % Direct calculation of Var[g(X,Y)] VG = 80.2133 [Z,PZ] = csort(G,P); % Determination of distribution for Z EZ = Z*PZ' % E[Z] from distribution EZ = 3.2529 VZ = (Z.^2)*PZ' - EZ^2 % Var[Z] from distribution VZ = 80.2133
Suppose X∼ exponential (0.3). Let
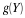
Determine E[Z] and 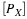 .
.
ANALYTIC SOLUTION