3 - Digging Through the Archives
Now that we picked a domain to explore, it's time to go back to the Wayback Machine and actually start digging through the archives to look for content that we can use.
For this example I'm going to look at “dogtraininghelpnow.com” which sounds like the kind of domain that would have useful articles about dog training.
Here's what Wayback Machine has on it:
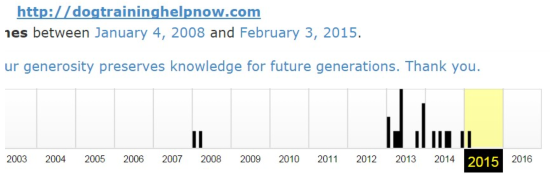
This is quite typical for many expired domains – you see just a handful of entries over the years and may have a gap of many years.
Now obviously I'm not going to investigate every single entry. Even with a site like this that only has a few, that would be far too time consuming. I begin by looking at one entry for each year. I typically start at the end of the year.
This is what I found for 2015:

Chinese spam! That's something you'll see a LOT of when using this method. The Chinese like to buy up old domains and just dump spam on them. So let's move on.
An entry near the end of 2014 brought back more Chinese spam so onto 2013...
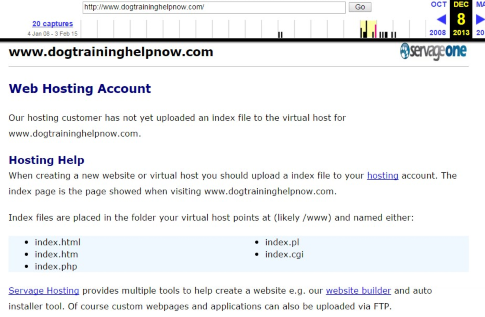
It looks like at this point the site was taken down. You'll also see lots of things like this, plus parked pages, pages that show “buy this domain” etc. None of those are useful obviously.
For this particular domain the only other entries now are way back in 2008. Lets see what that brings up:
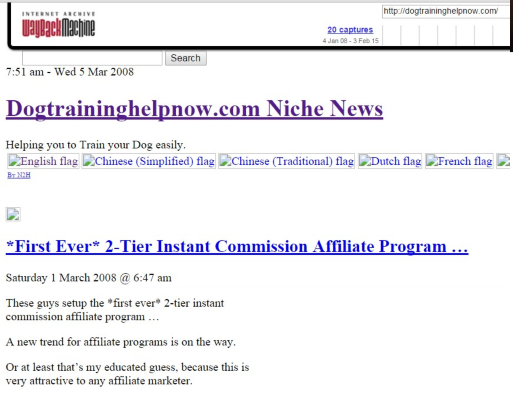
At first glance it just looks like another kind of spam as this obviously doesn't have much to do with dog training. However I was able to scroll down on this page and look what I found a little bit later on:
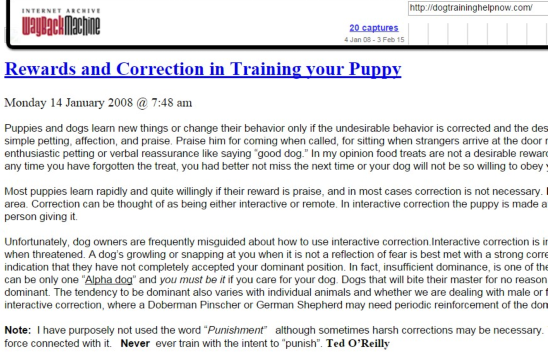
BINGO!!! Not only is this relevant but it is showing the full text of the post. This means we can copy the article straight out of the Wayback Machine page – that's exactly what we're looking for!
This particular page had 6 full blog posts about dog training and then underneath that I saw a lot more post excerpts that looked this:
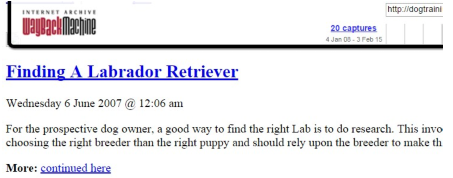
Ahh, not quite so good as we're only seeing a snippet of the full post.
Now this is where we need to be careful. If you hover over the “continued here” link you think you're going to be taken to the blog post but in actual fact it is a link to Ezine articles!
What you really want to click on in this case is the headline “Finding a Labrador Retriever”.
This is a link to an internal page on the site and now we hope that Wayback has crawled the page so we can extract the rest of the article from it.
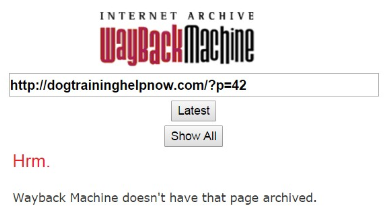
That error message is one that you will grow to hate using this method. In my experience I have found that in the vast majority of cases only the home page of a site is crawled and it's not very often that I find deeper links that have been crawled.
It's always worth checking though.
Searching From Oldest to Newest
In this example I began my search at the latest entry which was in 2015 and I worked backwards. I did this simply to illustrate the kinds of results you might see such as Chinese spam and page not found errors.
However in practice, I always do my searches the other way around. Whoever first created that domain was the purpose who first had the idea for the content so the most likely time that the site would have had real content on it is when it was first created.
Once the site has expired and been picked up by somebody else to be re-purposed in some way, in almost all case, it gets used for some kind of spam and rarely do you find any good content to use.
There are exceptions of course but in order to minimize the time spent with this method I tend to quickly scan the early entries and if I don't find anything, I'll check one or two of the later years and then just move onto the next domain is nothing good is found.