Chapter 5
Shared-Memory Multiprocessors
5.1 Introduction1
5.1.1 Shared-Memory Multiprocessors
In the mid-1980s, shared-memory multiprocessors were pretty expensive and pretty rare. Now, as hardware costs are dropping, they are becoming commonplace. Many home computer systems in the under-$3000 range have a socket for a second CPU. Home computer operating systems are providing the capability to use more than one processor to improve system performance. Rather than specialized resources locked away in a central computing facility, these shared-memory processors are often viewed as a logical extension of the desktop. These systems run the same operating system (UNIX or NT) as the desktop and many of the same applications from a workstation will execute on these multiprocessor servers.
Typically a workstation will have from 1 to 4 processors and a server system will have 4 to 64 processors.
Shared-memory multiprocessors have a signicant advantage over other multiprocessors because all the processors share the same view of the memory, as shown in Figure 10-1.
These processors are also described as uniform memory access (also known as UMA) systems. This designation indicates that memory is equally accessible to all processors with the same performance.
The popularity of these systems is not due simply to the demand for high performance computing. These systems are excellent at providing high throughput for a multiprocessing load, and function eectively as high-performance database servers, network servers, and Internet servers. Within limits, their throughput is increased linearly as more processors are added.
In this book we are not so interested in the performance of database or Internet servers. That is too passé; buy more processors, get better throughput. We are interested in pure, raw, unadulterated compute speed for our high performance application. Instead of running hundreds of small jobs, we want to utilize all $750,000 worth of hardware for our single job.
The challenge is to nd techniques that make a program that takes an hour to complete using one processor, complete in less than a minute using 64 processors. This is not trivial. Throughout this book so far, we have been on an endless quest for parallelism. In this and the remaining chapters, we will begin to see the payo for all of your hard work and dedication!
The cost of a shared-memory multiprocessor can range from $4000 to $30 million. Some example systems include multiple-processor Intel systems from a wide range of vendors, SGI Power Challenge Series, HP/Convex C-Series, DEC AlphaServers, Cray vector/parallel processors, and Sun Enterprise systems. The SGI Origin 2000, HP/Convex Exemplar, Data General AV-20000, and Sequent NUMAQ-2000 all are uniform-memory, symmetric multiprocessing systems that can be linked to form even larger shared nonuniform memory-access systems. Among these systems, as the price increases, the number of CPUs increases, the performance of individual CPUs increases, and the memory performance increases.
1This content is available online at <http://cnx.org/content/m32797/1.1/>.
In this chapter we will study the hardware and software environment in these systems and learn how to execute our programs on these systems.
5.2 Symmetric Multiprocessing Hardware2
5.2.1 Symmetric Multiprocessing Hardware
In Figure 5.1 (Figure 10-1: A shared-memory multiprocessor), we viewed an ideal shared-memory multiprocessor. In this section, we look in more detail at how such a system is actually constructed. The primary advantage of these systems is the ability for any CPU to access all of the memory and peripherals. Furthermore, the systems need a facility for deciding among themselves who has access to what, and when, which means there will have to be hardware support for arbitration. The two most common architectural underpinnings for symmetric multiprocessing are buses and crossbars. The bus is the simplest of the two approaches. Figure 5.2 shows processors connected using a bus. A bus can be thought of as a set of parallel wires connecting the components of the computer (CPU, memory, and peripheral controllers), a set of protocols for communication, and some hardware to help carry it out. A bus is less expensive to build, but because all trac must cross the bus, as the load increases, the bus eventually becomes a performance bottleneck.
Figure 10-1: A shared-memory multiprocessor
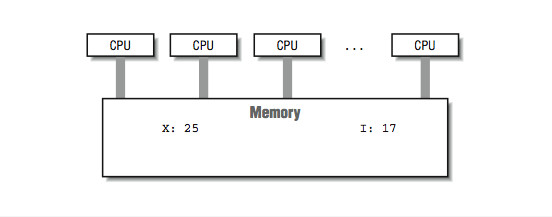
Figure 5.1
2This content is available online at <http://cnx.org/content/m32794/1.1/>.
Figure 5.2:
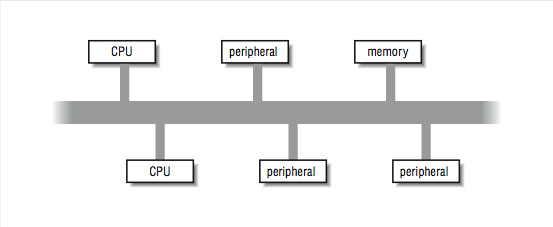
Figure 10-2: A typical bus architecture
A crossbar is a hardware approach to eliminate the bottleneck caused by a single bus. A crossbar is like several buses running side by side with attachments to each of the modules on the machine CPU, memory, and peripherals. Any module can get to any other by a path through the crossbar, and multiple paths may be active simultaneously. In the 4×5 crossbar of Figure 5.3, for instance, there can be four active data transfers in progress at one time. In the diagram it looks like a patchwork of wires, but there is actually quite a bit of hardware that goes into constructing a crossbar. Not only does the crossbar connect parties that wish to communicate, but it must also actively arbitrate between two or more CPUs that want access to the same memory or peripheral. In the event that one module is too popular, it's the crossbar that decides who gets access and who doesn't. Crossbars have the best performance because there is no single shared bus. However, they are more expensive to build, and their cost increases as the number of ports is increased. Because of their cost, crossbars typically are only found at the high end of the price and performance spectrum.
Whether the system uses a bus or crossbar, there is only so much memory bandwidth to go around; four or eight processors drawing from one memory system can quickly saturate all available bandwidth. All of the techniques that improve memory performance (as described in Chapter 3, Memory) also apply here in the design of the memory subsystems attached to these buses or crossbars.
Figure 5.3:
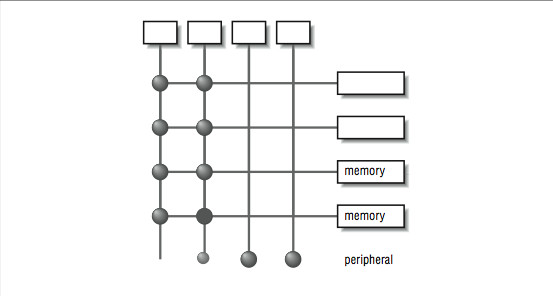
Figure 10-3: A crossbar
5.2.1.1 The Eect of Cache
The most common multiprocessing system is made up of commodity processors connected to memory and peripherals through a bus. Interestingly, the fact that these processors make use of cache somewhat mitigates the bandwidth bottleneck on a bus-based architecture. By connecting the processor to the cache and viewing the main memory through the cache, we signicantly reduce the memory trac across the bus. In this architecture, most of the memory accesses across the bus take the form of cache line loads and ushes. To understand why, consider what happens when the cache hit rate is very high. In Figure 5.4, a high cache hit rate eliminates some of the trac that would have otherwise gone out across the bus or crossbar to main memory. Again, it is the notion of locality of reference that makes the system work. If you assume that a fair number of the memory references will hit in the cache, the equivalent attainable main memory bandwidth is more than the bus is actually capable of. This assumption explains why multiprocessors are designed with less bus bandwidth than the sum of what the CPUs can consume at once.
Imagine a scenario where two CPUs are accessing dierent areas of memory using unit stride. Both CPUs access the rst element in a cache line at the same time. The bus arbitrarily allows one CPU access to the memory. The rst CPU lls a cache line and begins to process the data. The instant the rst CPU has completed its cache line ll, the cache line ll for the second CPU begins. Once the second cache line ll has completed, the second CPU begins to process the data in its cache line. If the time to process the data in a cache line is longer than the time to ll a cache line, the cache line ll for processor two completes before the next cache line request arrives from processor one. Once the initial conict is resolved, both processors appear to have conict-free access to memory for the remainder of their unit-stride loops.
Figure 5.4:
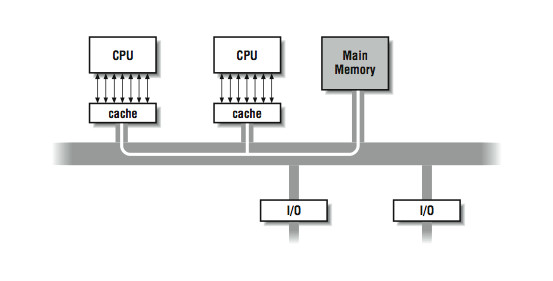
Figure 10-4: High cache hit rate reduces main memory trac
In actuality, on some of the fastest bus-based systems, the memory bus is suciently fast that up to 20 processors can access memory using unit stride with very little conict. If the processors are accessing memory using non-unit stride, bus and memory bank conict becomes apparent, with fewer processors.
This bus architecture combined with local caches is very popular for general-purpose multiprocessing loads. The memory reference patterns for database or Internet servers generally consist of a combination of time periods with a small working set, and time periods that access large data structures using unit stride.
Scientic codes tend to perform more non-unit-stride access than general-purpose codes. For this reason, the most expensive parallel-processing systems targeted at scientic codes tend to use crossbars connected to multibanked memory systems.
The main memory system is better shielded when a larger cache is used. For this reason, multiprocessors sometimes incorporate a two-tier cache system, where each processor uses its own small on-chip local cache, backed up by a larger second board-level cache with as much as 4 MB of memory. Only when neither can satisfy a memory request, or when data has to be written back to main memory, does a request go out over the bus or crossbar.
5.2.1.2 Coherency
Now, what happens when one CPU of a multiprocessor running a single program in parallel changes the
value of a variable, and another CPU tries to read it? Where does the value come from? These questions are interesting because there can be multiple copies of each variable, and some of them can hold old or stale values.
For illustration, say that you are running a program with a shared variable A. Processor 1 changes the value of A and Processor 2 goes to read it.
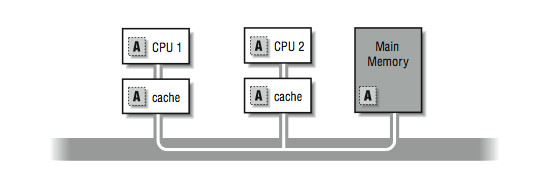
Figure 5.
5: Figure 10-5: Multiple copies of variable A
In Figure 5.5, if Processor 1 is keeping A as a register-resident variable, then Processor 2 doesn't stand a chance of getting the correct value when it goes to look for it. There is no way that 2 can know the contents of 1's registers; so assume, at the very least, that Processor 1 writes the new value back out. Now the question is, where does the new value get stored? Does it remain in Processor 1's cache? Is it written to main memory? Does it get updated in Processor 2's cache?
Really, we are asking what kind of cache coherency protocol the vendor uses to assure that all processors see a uniform view of the values in memory. It generally isn't something that the programmer has to worry about, except that in some cases, it can aect performance. The approaches used in these systems are similar to those used in single-processor systems with some extensions. The most straight-forward cache coherency approach is called a write-through policy : variables written into cache are simultaneously written into main memory. As the update takes place, other caches in the system see the main memory reference being performed. This can be done because all of the caches continuously monitor (also known as snooping ) the trac on the bus, checking to see if each address is in their cache. If a cache notices that it contains a copy of the data from the locations being written, it may either invalidate its copy of the variable or obtain new values (depending on the policy). One thing to note is that a write-through cache demands a fair amount of main memory bandwidth since each write goes out over the main memory bus. Furthermore, successive writes to the same location or bank are subject to the main memory cycle time and can slow the machine down.
A more sophisticated cache coherency protocol is called copyback or writeback. The idea is that you write values back out to main memory only when the cache housing them needs the space for something else.
Updates of cached data are coordinated between the caches, by the caches, without help from the processor.
Copyback caching also uses hardware that can monitor (snoop) and respond to the memory transactions of the other caches in the system. The benet of this method over the write-through method is that memory trac is reduced considerably. Let's walk through it to see how it works.
5.2.1.3 Cache Line States
For this approach to work, each cache must maintain a state for each line in its cache. The possible states used in the example include:
Modied: This cache line needs to be written back to memory.
Exclusive: There are no other caches that have this cache line.
Shared : There are read-only copies of this line in two or more caches.
Empty/Invalid: This cache line doesn't contain any useful data.
This particular coherency protocol is often called MESI. Other cache coherency protocols are more complicated, but these states give you an idea how multiprocessor writeback cache coherency works.
We start where a particular cache line is in memory and in none of the writeback caches on the systems.
The rst cache to ask for data from a particular part of memory completes a normal memory access; the main memory system returns data from the requested location in response to a cache miss. The associated cache line is marked exclusive, meaning that this is the only cache in the system containing a copy of the data; it is the owner of the data. If another cache goes to main memory looking for the same thing, the request is intercepted by the rst cache, and the data is returned from the rst cache not main memory.
Once an interception has occurred and the data is returned, the data is marked shared in both of the caches.
When a particular line is marked shared, the caches have to treat it dierently than they would if they were the exclusive owners of the data especially if any of them wants to modify it. In particular, a write to a shared cache entry is preceded by a broadcast message to all the other caches in the system. It tells them to invalidate their copies of the data. The one remaining cache line gets marked as modied to signal that it has been changed, and that it must be returned to main memory when the space is needed for something else. By these mechanisms, you can maintain cache coherence across the multiprocessor without adding tremendously to the memory trac.
By the way, even if a variable is not shared, it's possible for copies of it to show up in several caches.
On a symmetric multiprocessor, your program can bounce around from CPU to CPU. If you run for a little while on this CPU, and then a little while on that, your program will have operated out of separate caches.
That means that there can be several copies of seemingly unshared variables scattered around the machine.
Operating systems often try to minimize how often a process is moved between physical CPUs during context switches. This is one reason not to overload the available processors in a system.
5.2.1.4 Data Placement
There is one more pitfall regarding shared memory we have so far failed to mention. It involves data movement. Although it would be convenient to think of the multiprocessor memory as one big pool, we have seen that it is actually a carefully crafted system of caches, coherency protocols, and main memory. The problems come when your application causes lots of data to be traded between the caches. Each reference that falls out of a given processor's cache (especially those that require an update in another processor's cache) has to go out on the bus.
Often, it's slower to get memory from another processor's cache than from the main memory because of the protocol and processing overhead involved. Not only do we need to have programs with high locality of reference and unit stride, we also need to minimize the data that must be moved from one CPU to another.
5.3 Multiprocessor Software Concepts 3
5.3.1 Multiprocessor Software Concepts
Now that we have examined the way shared-memory multiprocessor hardware operates, we need to examine how software operates on these types of computers. We still have to wait until the next chapters to begin making our FORTRAN programs run in parallel. For now, we use C programs to examine the fundamentals of multiprocessing and multithreading. There are several techniques used to implement multithreading, so the topics we will cover include:
• Operating systemsupported multiprocessing
• User space multithreading
• Operating system-supported multithreading
The last of these is what we primarily will use to reduce the walltime of our applications.
3This content is available online at <http://cnx.org/content/m32800/1.1/>.
5.3.1.1 Operating SystemSupported Multiprocessing
Most modern general-purpose operating systems support some form of multiprocessing. Multiprocessing doesn't require more than one physical CPU; it is simply the operating system's ability to run more than one process on the system. The operating system context-switches between each process at xed time intervals, or on interrupts or input-output activity. For example, in UNIX, if you use the ps command, you can see the processes on the system:

For each process we see the process identier (PID), the terminal that is executing the command, the amount of CPU time the command has used, and the name of the command. The PID is unique across the entire system. Most UNIX commands are executed in a separate process. In the above example, most of the processes are waiting for some type of event, so they are taking very few resources except for memory.
Process 67734 seems to be executing and using resources. Running ps again conrms that the CPU time is increasing for the ansys process:

Running the vmstat 5 command tells us many things about the activity on the system. First, there are three runnable processes. If we had one CPU, only one would actually be running at a given instant. To allow all three jobs to progress, the operating system time-shares between the processes. Assuming equal priority, each process executes about 1/3 of the time. However, this system is a two-processor system, so each process executes about 2/3 of the time. Looking across the vmstat output, we can see paging activity (pi, po), context switches (cs), overall user time (us), system time (sy), and idle time (id ).
Each process can execute a completely dierent program. While most processes are completely independent, they can cooperate and share information using interprocess communication (pipes, sockets) or various operating system-supported shared-memory areas. We generally don't use multiprocessing on these shared-memory systems as a technique to increase single-application performance. We will explore techniques that use multiprocessing coupled with communication to improve performance on scalable parallel processing systems in Chapter 12, Large- Scale Parallel Computing.
4ANSYS is a commonly used structural-analysis package.
5.3.1.2 Multiprocessing software
In this section, we explore how programs access multiprocessing features.5 In this example, the program creates a new process using the fork( ) function. The new process (child) prints some messages and then changes its identity using exec( ) by loading a new program. The original process (parent) prints some messages and then waits for the child process to complete:

The key to understanding this code is to understand how the fork( ) function operates. The simple summary is that the fork( ) function is called once in a process and returns twice, once in the original process and once in a newly created process. The newly created process is an identical copy of the original process. All the variables (local and global) have been duplicated. Both processes have access to all of the open les of the original process. Figure 5.6 (Figure 10-6: How a fork operates) shows how the fork operation creates a new process.
5These examples are written in C using the POSIX 1003.1 application programming interface. This example runs on most UNIX systems and on other POSIX-compliant systems including OpenNT, Open- VMS, and many others.
The only dierence between the processes is that the return value from the fork( ) function call is 0 in the new (child) process and the process identier (shown by the ps command) in the original (parent) process. This is the program output:

Tracing this through, rst the program sets the global and stack variable to one and then calls fork( ).
During the fork( ) call, the operating system suspends the process, makes an exact duplicate of the process, and then restarts both processes. You can see two messages from the statement immediately after the fork.
The rst line is coming from the original process, and the second line is coming from the new process. If you were to execute a ps command at this moment in time, you would see two processes running called fork.
One would have a process identier of 19336.
Figure 10-6: How a fork operates
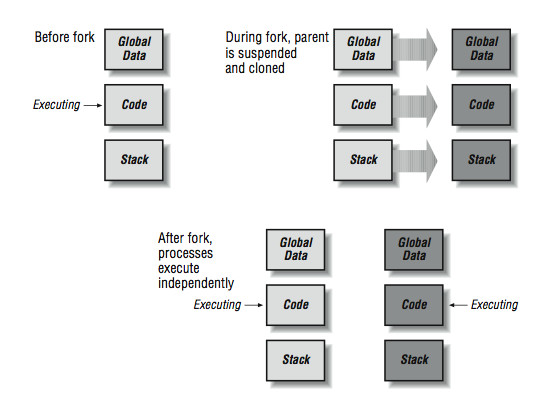
Figure 5.6
As both processes start, they execute an IF-THEN-ELSE and begin to perform dierent actions in the parent and child. Notice that globvar and stackvar are set to 5 in the parent, and then the parent sleeps for two seconds. At this point, the child begins executing. The values for globvar and stackvar are unchanged in the child process. This is because these two processes are operating in completely independent memory spaces. The child process sleeps for one second and sets its copies of the variables to 100. Next, the child process calls the execl( ) function to overwrite its memory space with the UNIX date program. Note that the execl( ) never returns; the date program takes over all of the resources of the child process. If you were to do a ps at this moment in time, you still see two processes on the system but process 19336 would be called date. The date command executes, and you can see its output.6
The parent wakes up after a brief two-second sleep and notices that its copies of global and local variables have not been changed by the action of the child process. The parent then calls the wait( ) function to 6It's not uncommon for a human parent process to fork and create a human child process that initially seems to have the same identity as the parent. It's also not uncommon for the child process to change its overall identity to be something very dierent from the parent at some later point. Usually human children wait 13 years or so before this change occurs, but in UNIX, this happens in a few microseconds. So, in some ways, in UNIX, there are many parent processes that are disappointed because their children did not turn out like them determine if any of its children exited. The wait( ) function returns which child has exited and the status code returned by that child process (in this case, process 19336).
5.3.1.3 User Space Multithreading
A thread is dierent from a process. When you add threads, they are added to the existing process rather than starting in a new process. Processes start with a single thread of execution and can add or remove threads throughout the duration of the program. Unlike processes, which operate in dierent memory spaces, all threads in a process share the same memory space. Figure 10-7 shows how the creation of a thread diers from the creation of a process. Not all of the memory space in a process is shared between all threads. In addition to the global area that is shared across all threads, each thread has a thread private area for its own local variables. It's important for programmers to know when they are working with shared variables and when they are working with local variables.
When attempting to speed up high performance computing applications, threads have the advantage over processes in that multiple threads can cooperate and work on a shared data structure to hasten the computation. By dividing the work into smaller portions and assigning each smaller portion to a separate thread, the total work can be completed more quickly.
Multiple threads are also used in high performance database and Internet servers to improve the overall throughput of the server. With a single thread, the program can either be waiting for the next network request or reading the disk to satisfy the previous request. With multiple threads, one thread can be waiting for the next network transaction while several other threads are waiting for disk I/O to complete.
The following is an example of a simple multithreaded application.7 It begins with a single master thread that creates three additional threads. Each thread prints some messages, accesses some global and local variables, and then terminates:

7This example uses the IEEE POSIX standard interface for a thread library. If your system supports POSIX threads, this example should work. If not, there should be similar routines on your system for each of the thread functions.

Figure 10-7: Creating a thread
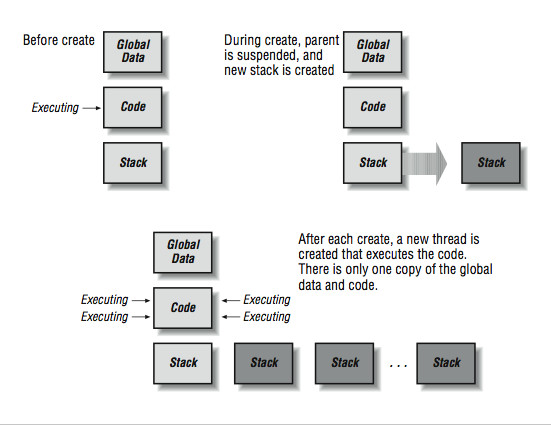
Figure 5.7
The global shared areas in this case are those variables declared in the static area outside the main( ) code.
The local variables are any variables declared within a routine. When threads are added, each thread gets its own function call stack. In C, the automatic variables that are declared at the beginning of each routine are allocated on the stack. As each thread enters a function, these variables are separately allocated on that particular thread's stack. So these are the thread-local variables.
Unlike the fork( ) function, the pthread_create( ) function creates a new thread, and then control is returned to the calling thread. One of the parameters of the pthread_create( ) is the name of a function.
New threads begin execution in the function TestFunc( ) and the thread nishes when it returns from this function. When this program is executed, it produces the following output:
recs % cc -o create1 -lpthread -lposix4 create1.c
recs % create1

You can see the threads getting created in the loop. The master thread completes the pthread_create( ) loop, executes the second loop, and calls the pthread_join( ) function. This function suspends the master thread until the specied thread completes. The master thread is waiting for Thread 4 to complete. Once the master thread suspends, one of the new threads is started. Thread 4 starts executing. Initially the variable globvar is set to 0 from the main program. The self, me, and param variables are thread-local variables, so each thread has its own copy. Thread 4 sets globvar to 15 and goes to sleep. Then Thread 5
begins to execute and sees globvar set to 15 from Thread 4; Thread 5 sets globvar to 16, and goes to sleep.
This activates Thread 6, which sees the current value for globvar and sets it to 17. Then Threads 6, 5, and 4 wake up from their sleep, all notice the latest value of 17 in globvar, and return from the TestFunc( ) routine, ending the threads.
All this time, the master thread is in the middle of a pthread_join( ) waiting for Thread 4 to complete.
As Thread 4 completes, the pthread_join( ) returns. The master thread then calls pthread_join( ) repeatedly to ensure that all three threads have been completed. Finally, the master thread prints out the value for globvar that contains the latest value of 17.
To summarize, when an application is executing with more than one thread, there are shared global areas and thread private areas. Dierent threads execute at dierent times, and they can easily work together in shared areas.
5.3.1.4 Limitations of user space multithreading
Multithreaded applications were around long before multiprocessors existed. It is quite practical to have multiple threads with a single CPU. As a matter of fact, the previous example would run on a system with any number of processors, including one. If you look closely at the code, it performs a sleep operation at each critical point in the code. One reason to add the sleep calls is to slow the program down enough that you can actually see what is going on. However, these sleep calls also have another eect. When one thread enters the sleep routine, it causes the thread library to search for other runnable threads. If a runnable thread is found, it begins executing immediately while the calling thread is sleeping. This is called a user-space thread context switch. The process actually has one operating system thread shared among several logical user threads. When library routines (such as sleep) are called, the thread library8 jumps in and reschedules threads.
We can explore this eect by substituting the