Introduction
Frequently, we observe a value of some random variable, but are really interested in a value derived from this by a function rule. If X is a random variable and g is a reasonable function (technically, a Borel function), then Z=g(X) is a new random variable which has the value g(t) for any ω such that X(ω)=t. Thus Z(ω)=g(X(ω)).
We consider, first, functions of a single random variable. A wide variety of functions are utilized in practice.
In a quality control check on a production line for ball bearings it may be easier to weigh the balls than measure the diameters. If we can assume true spherical shape and w is the weight, then diameter is kw1/3, where k is a factor depending upon the formula for the volume of a sphere, the units of measurement, and the density of the steel. Thus, if X is the weight of the sampled ball, the desired random variable is D=kX1/3.
The cultural committee of a student organization has arranged a special deal for tickets to a concert. The agreement is that the organization will purchase ten tickets at $20 each (regardless of the number of individual buyers). Additional tickets are available according to the following schedule:
11-20, $18 each
21-30, $16 each
31-50, $15 each
51-100, $13 each
If the number of purchasers is a random variable X, the total cost (in dollars) is a random quantity Z=g(X) described by
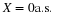
The function rule is more complicated than in Example 10.1, but the essential problem is the same.
The problem
If X is a random variable, then Z=g(X) is a new random variable. Suppose we have the distribution for X. How can we determine P(Z∈M), the probability Z takes a value in the set M?
An approach to a solution
We consider two equivalent approaches
To find P(X∈M).
Mapping approach. Simply find the amount of probability mass mapped into the set M by the random variable X.
In the absolutely continuous case, calculate 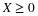 .
.
In the discrete case, identify those values ti of X which are in the set M and add the associated probabilities.
Discrete alternative. Consider each value ti of X. Select those which meet the defining conditions for M and add the associated probabilities. This is the approach we use in the MATLAB calculations. Note that it is not necessary to describe geometrically the set M; merely use the defining conditions.
To find P(g(X)∈M).
Mapping approach. Determine the set N of all those t which are mapped into M by the function g. Now if X(ω)∈N, then g(X(ω))∈M, and if g(X(ω))∈M, then X(ω)∈N. Hence
Since these are the same event, they must have the same probability. Once N is identified, determine P(X∈N) in the usual manner (see part a, above).
Discrete alternative. For each possible value ti of X, determine
whether  meets the defining condition for M. Select those ti which do and
add the associated probabilities.
meets the defining condition for M. Select those ti which do and
add the associated probabilities.
— □
Remark. The set N in the mapping approach is called the inverse image N=g–1(M).
Suppose X has values -2, 0, 1, 3, 6, with respective probabilities 0.2, 0.1, 0.2, 0.3 0.2.
Consider Z=g(X)=(X+1)(X–4). Determine P(Z>0).
SOLUTION
First solution. The mapping approach
g(t)=(t+1)(t–4). N={t:g(t)>0} is the set of points to the left of –1 or to the right of 4. The X-values –2 and 6 lie in this set. Hence
Second solution. The discrete alternative
| X = | -2 | 0 | 1 | 3 | 6 |
| P X = | 0.2 | 0.1 | 0.2 | 0.3 | 0.2 |
| Z = | 6 | -4 | -6 | -4 | 14 |
| Z > 0 | 1 | 0 | 0 | 0 | 1 |
Picking out and adding the indicated probabilities, we have
In this case (and often for “hand calculations”) the mapping approach requires less calculation. However, for MATLAB calculations (as we show below), the discrete alternative is more readily implemented.
Suppose X∼ uniform [–3,7]. Then fX(t)=0.1,–3≤t≤7 (and zero elsewhere). Let
Determine P(Z>0).
SOLUTION
First we determine N={t:g(t)>0}. As in Example 10.3, g(t)=(t+1)(t–4)>0
for t<–1 or t>4. Because of the uniform distribution, the integral of the density
over any subinterval of 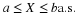 is 0.1 times the length of that subinterval. Thus, the
desired probability is
is 0.1 times the length of that subinterval. Thus, the
desired probability is
We consider, next, some important examples.
To show that if 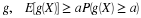 then
then
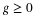
VERIFICATION
We wish to show the denity function for Z is
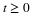
Now
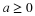
Hence, for given 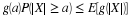 the inverse image is
the inverse image is 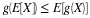 , so that
, so that
Since the density is the derivative of the distribution function,
Thus
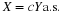
We conclude that