This module provides an overview of the sensing matrix design problem in compressive sensing.
In order to make the discussion more concrete, we will restrict our attention to the standard finite-dimensional compressive sensing (CS) model. Specifically, given a signal x∈RN, we consider measurement systems that acquire M linear measurements. We can represent this process mathematically as
where Φ is an M×N matrix and y∈RM. The matrix Φ represents a dimensionality reduction, i.e., it maps RN, where N is generally large, into RM, where M is typically much smaller than N. Note that in the standard CS framework we assume that the measurements are non-adaptive, meaning that the rows of Φ are fixed in advance and do not depend on the previously acquired measurements. In certain settings adaptive measurement schemes can lead to significant performance gains.
Note that although the standard CS framework assumes that x is a finite-length vector with a discrete-valued index (such as time or space), in practice we will often be interested in designing measurement systems for acquiring continuously-indexed signals such as continuous-time signals or images. For now we will simply think of x as a finite-length window of Nyquist-rate samples, and we temporarily ignore the issue of how to directly acquire compressive measurements without first sampling at the Nyquist rate.
There are two main theoretical questions in CS. First, how should we design the sensing matrix Φ to ensure that it preserves the information in the signal x? Second, how can we recover the original signal x from measurements y? In the case where our data is sparse or compressible, we will see that we can design matrices Φ with M≪N that ensure that we will be able to recover the original signal accurately and efficiently using a variety of practical algorithms.
We begin in this part of the course by first addressing the question of how to design the sensing matrix Φ. Rather than directly proposing a design procedure, we instead consider a number of desirable properties that we might wish Φ to have (including the null space property, the restricted isometry property, and bounded coherence). We then provide some important examples of matrix constructions that satisfy these properties.
This module introduces the spark and the null space property, two common conditions related to the null space of a measurement matrix that ensure the success of sparse recovery algorithms. Furthermore, the null space property is shown to be a necessary condition for instance optimal or uniform recovery guarantees.
A natural place to begin in establishing conditions on Φ in the context of designing a sensing matrix is by considering the null space of Φ, denoted
If we wish to be able to recover all sparse signals x from the measurements Φx, then it is immediately clear that for any pair of distinct vectors x,x'∈ΣK
=
{x : ∥x∥0 ≤ K}
, we must have Φx≠Φx', since otherwise it would be impossible to distinguish x from x' based solely on the measurements y. More formally, by observing that if Φx=Φx' then 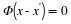 with x–x'∈Σ2K, we see that Φ uniquely represents all x∈ΣK if and only if N(Φ) contains no vectors in Σ2K. There are many equivalent ways of characterizing this property; one of the most common is known as the spark 2.
with x–x'∈Σ2K, we see that Φ uniquely represents all x∈ΣK if and only if N(Φ) contains no vectors in Σ2K. There are many equivalent ways of characterizing this property; one of the most common is known as the spark 2.
The spark of a given matrix Φ is the smallest number of columns of Φ that are linearly dependent.
This definition allows us to pose the following straightforward guarantee.
<ext:rule>For any vector y∈RM, there exists at most one signal x∈ΣK such that y=Φx if and only if spark (Φ)>2K.
We first assume that, for any y∈RM, there exists at most one signal x∈ΣK such that y=Φx. Now suppose for the sake of a contradiction that spark (Φ)≤2K. This means that there exists some set of at most 2K columns that are linearly independent, which in turn implies that there exists an h∈N(Φ) such that h∈Σ2K. In this case, since h∈Σ2K we can write h=x–x', where x,x'∈ΣK. Thus, since h∈N(Φ) we have that 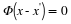 and hence Φx=Φx'. But this contradicts our assumption that there exists at most one signal x∈ΣK such that y=Φx. Therefore, we must have that spark (Φ)>2K.
and hence Φx=Φx'. But this contradicts our assumption that there exists at most one signal x∈ΣK such that y=Φx. Therefore, we must have that spark (Φ)>2K.
Now suppose that spark (Φ)>2K. Assume that for some y there exist x,x'∈ΣK such that y=Φx=Φx'. We therefore have that 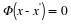 . Letting h=x–x', we can write this as Φh=0. Since spark (Φ)>2K, all sets of up to 2K columns of Φ are linearly independent, and therefore h=0. This in turn implies x=x', proving the theorem.
. Letting h=x–x', we can write this as Φh=0. Since spark (Φ)>2K, all sets of up to 2K columns of Φ are linearly independent, and therefore h=0. This in turn implies x=x', proving the theorem.
It is easy to see that spark (Φ)∈[2,M+1]. Therefore, Theorem 3.1. yields the requirement M≥2K.
When dealing with exactly sparse vectors, the spark provides a complete characterization of when sparse recovery is possible. However, when dealing with approximately sparse signals we must introduce somewhat more restrictive conditions on the null space of Φ 1. Roughly speaking, we must also ensure that N(Φ) does not contain any vectors that are too compressible in addition to vectors that are sparse. In order to state the formal definition we define the following notation that will prove to be useful throughout much of this course. Suppose that Λ⊂{1,2,⋯,N} is a subset of indices and let Λc={1,2,⋯,N}∖Λ. By xΛ we typically mean the length N vector obtained by setting the entries of x indexed by Λc to zero. Similarly, by ΦΛ we typically mean the M×N matrix obtained by setting the columns of Φ indexed by Λc to zero.[2]
A matrix Φ satisfies the null space property (NSP) of order K if there exists a constant C>0 such that,
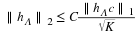
holds for all h∈N(Φ) and for all Λ such that |Λ|≤K.
The NSP quantifies the notion that vectors in the null space of Φ should not be too concentrated on a small subset of indices. For example, if a vector h is exactly K-sparse, then there exists a Λ such that ∥hΛc∥1=0 and hence Equation 3.3 implies that hΛ=0 as well. Thus, if a matrix Φ satisfies the NSP then the only K-sparse vector in N(Φ) is h=0.
To fully illustrate the implications of the NSP in the context of sparse recovery, we now briefly discuss how we will measure the performance of sparse recovery algorithms when dealing with general non-sparse x. Towards this end, let Δ:RM→RN represent our specific recovery method. We will focus primarily on guarantees of the form
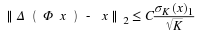
for all x, where we recall that
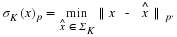
This guarantees exact recovery of all possible K-sparse signals, but also ensures a degree of robustness to non-sparse signals that directly depends on how well the signals are approximated by K-sparse vectors. Such guarantees are called instance-optimal since they guarantee optimal performance for each instance of x 1. This distinguishes them from guarantees that only hold for some subset of possible signals, such as sparse or compressible signals — the quality of the guarantee adapts to the particular choice of x. These are also commonly referred to as uniform guarantees since they hold uniformly for all x.
Our choice of norms in Equation 3.4 is somewhat arbitrary. We could easily measure the reconstruction error using other ℓp norms. The choice of p, however, will limit what kinds of guarantees are possible, and will also potentially lead to alternative formulations of the NSP. See, for instance, 1. Moreover, the form of the right-hand-side of Equation 3.4 might seem somewhat unusual in that we measure the approximation error as 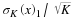 rather than simply something like σK(x)2. However, we will see later in this course that such a guarantee is actually not possible without taking a prohibitively large number of measurements, and that Equation 3.4 represents the best possible guarantee we can hope to obtain (see "Instance-optimal guarantees revisited").
rather than simply something like σK(x)2. However, we will see later in this course that such a guarantee is actually not possible without taking a prohibitively large number of measurements, and that Equation 3.4 represents the best possible guarantee we can hope to obtain (see "Instance-optimal guarantees revisited").
Later in this course, we will show that the NSP of order 2K is sufficient to establish a guarantee of the form Equation 3.4 for a practical recovery algorithm (see "Noise-free signal recovery"). Moreover, the following adaptation of a theorem in 1 demonstrates that if there exists any recovery algorithm satisfying Equation 3.4, then Φ must necessarily satisfy the NSP of order 2K.
<ext:rule>Let Φ:RN→RM denote a sensing matrix and Δ:RM→RN denote an arbitrary recovery algorithm. If the pair (Φ,Δ) satisfies Equation 3.4 then Φ satisfies the NSP of order 2K.
Suppose h∈N(Φ) and let Λ be the indices corresponding to the 2K largest entries of h. We next split Λ into Λ0 and Λ1, where |Λ0|=|Λ1|=K. Set