This module introduces and motivates ℓ_1 minimization as a framework for sparse recovery.
As we will see later in this course, there now exist a wide variety of approaches to recover a sparse signal x from a small number of linear measurements. We begin by considering a natural first approach to the problem of sparse recovery.
Given measurements y=Φx and the knowledge that our original signal x is sparse or compressible, it is natural to attempt to recover x by solving an optimization problem of the form
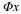
where B(y) ensures that 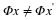 is consistent with the measurements y. Recall that ∥z∥0=| supp (z)| simply counts the number of nonzero entries in z, so Equation 4.1 simply seeks out the sparsest signal consistent with the observed measurements. For example, if our measurements are exact and noise-free, then we can set B(y)={z:Φz=y}. When the measurements have been contaminated with a small amount of bounded noise, we could instead set
is consistent with the measurements y. Recall that ∥z∥0=| supp (z)| simply counts the number of nonzero entries in z, so Equation 4.1 simply seeks out the sparsest signal consistent with the observed measurements. For example, if our measurements are exact and noise-free, then we can set B(y)={z:Φz=y}. When the measurements have been contaminated with a small amount of bounded noise, we could instead set 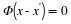 . In both cases, Equation 4.1 finds the sparsest x that is consistent with the measurements y.
. In both cases, Equation 4.1 finds the sparsest x that is consistent with the measurements y.
Note that in Equation 4.1 we are inherently assuming that x itself is sparse. In the more common setting where x=Ψα, we can easily modify the approach and instead consider
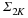
where B(y)={z:ΦΨz=y} or 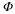 . By setting
. By setting 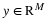 we see that Equation 4.1 and Equation 4.2 are essentially identical. Moreover, as noted in "Matrices that satisfy the RIP", in many cases the introduction of Ψ does not significantly complicate the construction of matrices Φ such that
we see that Equation 4.1 and Equation 4.2 are essentially identical. Moreover, as noted in "Matrices that satisfy the RIP", in many cases the introduction of Ψ does not significantly complicate the construction of matrices Φ such that 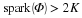 will satisfy the desired properties. Thus, for most of the remainder of this course we will restrict our attention to the case where Ψ=I. It is important to note, however, that this restriction does impose certain limits in our analysis when Ψ is a general dictionary and not an orthonormal basis. For example, in this case
will satisfy the desired properties. Thus, for most of the remainder of this course we will restrict our attention to the case where Ψ=I. It is important to note, however, that this restriction does impose certain limits in our analysis when Ψ is a general dictionary and not an orthonormal basis. For example, in this case 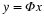 , and thus a bound on
, and thus a bound on 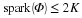 cannot directly be translated into a bound on
cannot directly be translated into a bound on 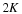 , which is often the metric of interest.
, which is often the metric of interest.
Although it is possible to analyze the performance of Equation 4.1 under the appropriate assumptions on Φ, we do not pursue this strategy since the objective function ∥·∥0 is nonconvex, and hence Equation 4.1 is potentially very difficult to solve. In fact, one can show that for a general matrix Φ, even finding a solution that approximates the true minimum is NP-hard. One avenue for translating this problem into something more tractable is to replace ∥·∥0 with its convex approximation ∥·∥1. Specifically, we consider
Provided that B(y) is convex, Equation 4.3 is computationally feasible. In fact, when B(y)={z:Φz=y}, the resulting problem can be posed as a linear program 2.
 (a)
Approximation in ℓ1 norm
|  (b)
Approximation in ℓp quasinorm
|
 .
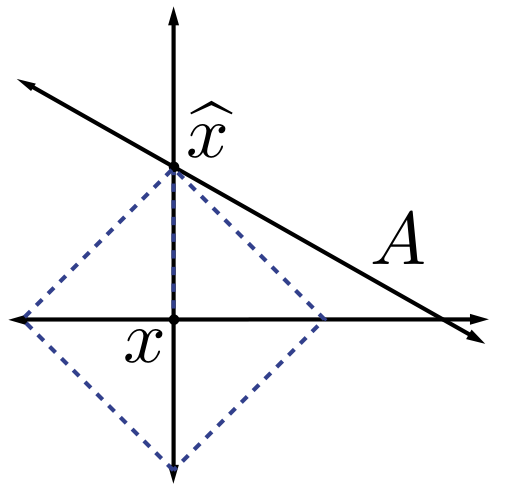
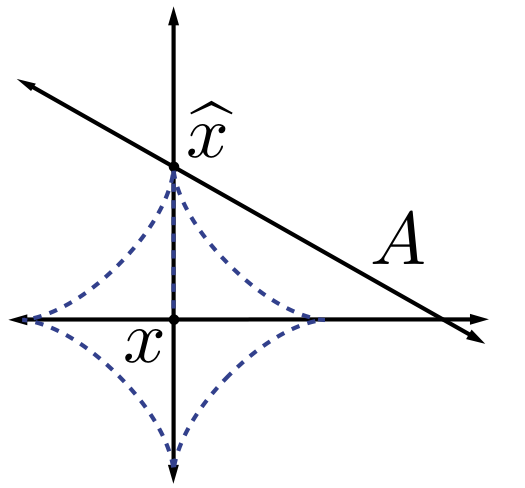
.It is clear that replacing Equation 4.1 with Equation 4.3 transforms a computationally intractable problem into a tractable one, but it may not be immediately obvious that the solution to Equation 4.3 will be at all similar to the solution to Equation 4.1. However, there are certainly intuitive reasons to expect that the use of ℓ1 minimization will indeed promote sparsity. As an example, recall the example we discussed earlier shown in Figure 4.1. In this case the solutions to the ℓ1 minimization problem coincided exactly with the solution to the ℓp minimization problem for any p<1, and notably, is sparse. Moreover, the use of ℓ1 minimization to promote or exploit sparsity has a long history, dating back at least to the work of Beurling on Fourier transform extrapolation from partial observations 1.
Additionally, in a somewhat different context, in 1965 Logan 4 showed that a bandlimited signal can be perfectly recovered in the presence of arbitrary corruptions on a small interval. Again, the recovery method consists of searching for the bandlimited signal that is closest to the observed signal in the ℓ1 norm. This can be viewed as further validation of the intuition gained from Figure 4.1 — the ℓ1 norm is well-suited to sparse errors.
Historically, the use of ℓ1 minimization on large problems finally became practical with the explosion of computing power in the late 1970's and early 1980's. In one of its first applications, it was demonstrated that geophysical signals consisting of spike trains could be recovered from only the high-frequency components of these signals by exploiting ℓ1 minimization 3, 6, 8. Finally, in the 1990's there was renewed interest in these approaches within the signal processing community for the purpose of finding sparse approximations to signals and images when represented in overcomplete dictionaries or unions of bases 2, 5. Separately, ℓ1 minimization received significant attention in the statistics literature as a method for variable selection in linear regression, known as the Lasso 7.
Thus, there are a variety of reasons to suspect that ℓ1 minimization will provide an accurate method for sparse signal recovery. More importantly, this also provides a computationally tractable approach to the sparse signal recovery problem. We now provide an overview of ℓ1 minimization in both the noise-free and noisy settings from a theoretical perspective. We will then further discuss algorithms for performing ℓ1 minimization later in this course.
Beurling, A. (1938). Sur les intégrales de Fourier absolument convergentes et leur application à une transformation fonctionelle. In Proc. Scandinavian Math. Congress. Helsinki, Finland
Chen, S. and Donoho, D. and Saunders, M. (1998). Atomic decomposition by basis pursuit. SIAM J. Sci. Comp., 20(1), 33–61.
Levy, S. and Fullagar, P. (1981). Reconstruction of a sparse spike train from a portion of its spectrum and application to high-resolution deconvolution. Geophysics, 46(9), 1235–1243.
Logan, B. (1965). Properties of High-Pass Signals. Ph. D. Thesis. Columbia Universuty.
Mallat, S. (1999). A Wavelet Tour of Signal Processing. San Diego, CA: Academic Press.
Taylor, H. and Banks, S. and McCoy, J. (1979). Deconvolution with the norm. Geophysics, 44(1), 39–52.
Tibshirani, R. (1996). Regression shrinkage and selection via the Lasso. J. Royal Statist. Soc B, 58(1), 267–288.
Walker, C. and Ulrych, T. (1983). Autoregressive recovery of the acoustic impedance. Geophysics, 48(10), 1338–1350.
This module establishes a simple performance guarantee of L1 minimization for signal recovery with noise-free measurements.
We now begin our analysis of
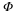
for various specific choices of B(y). In order to do so, we require the following general result which builds on Lemma 4 from "ℓ1 minimization proof". The key ideas in this proof follow from 1.
<ext:rule> Suppose that Φ satisfies the restricted isometry property (RIP) of order 2K with 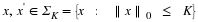 . Let be given, and define
. Let be given, and define 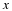 . Let Λ0 denote the index set corresponding to the K entries of x with largest magnitude and Λ1 the index set corresponding to the K entries of hΛ0c with largest magnitude. Set Λ=Λ0∪Λ1. If
. Let Λ0 denote the index set corresponding to the K entries of x with largest magnitude and Λ1 the index set corresponding to the K entries of hΛ0c with largest magnitude. Set Λ=Λ0∪Λ1. If 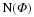 , then
, then
where
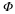
We begin by observing that h=hΛ+hΛc, so that from the triangle inequality
We first aim to bound ∥hΛc∥2. From Lemma 3 from "ℓ1 minimization proof" we have
where the Λj are defined as before, i.e., Λ1 is the index set corresponding to the K largest entries of hΛ0c (in absolute value), Λ2 as the index set corresponding to the next K largest entries, and so on.
We now wish to bound ∥hΛ0c∥1. Since 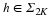 , by applying the triangle inequality we obtain
, by applying the triangle inequality we obtain
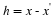
Rearranging and again applying the triangle inequality,
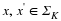
Recalling that σK(x)1=∥xΛ0c∥1=∥x – xΛ0∥1,
Combining this with Equation 4.8 we obtain
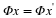
where the last inequality follows from standard bounds on ℓp norms (Lemma 1 from "The RIP and the NSP"). By observing that ∥hΛ0∥2≤∥hΛ∥2 this combines with Equation 4.7 to yield
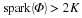
We now turn to establishing a bound for ∥hΛ∥2. Combining Lemma 4 from "ℓ1 minimization proof" with Equation 4.11 and again applying standard bounds on ℓp norms we obtain
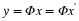
Since ∥hΛ0∥2≤∥hΛ∥2,
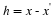
The assumption that  ensures that α<1. Dividing by
ensures that α<1. Dividing by