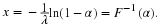Once a model is specified with its parameters and data have been collected, one is in a position to evaluate the model’s goodness of fit, that is, how well the model fits the observed pattern of data. Finding parameter values of a model that best fits the data — a procedure called parameter estimation, which assesses goodness of fit.
There are two generally accepted methods of parameter estimation. They are least squares estimation (LSE) and maximum likelihood estimation (MLE). The former is well known as linear regression, the sum of squares error, and the root means squared deviation is tied to the method. On the other hand, MLE is not widely recognized among modelers in psychology, though it is, by far, the most commonly used method of parameter estimation in the statistics community. LSE might be useful for obtaining a descriptive measure for the purpose of summarizing observed data, but MLE is more suitable for statistical inference such as model comparison. LSE has no basis for constructing confidence intervals or testing hypotheses whereas both are naturally built into MLE.
UNBIASED AND BIASED ESTIMATORS
Let consider random variables for which the functional form of the p.d.f. is know, but the distribution depends on an unknown parameter θ , that may have any value in a set θ , which is called the parameter space. In estimation the random sample from the distribution is taken to elicit some information about the unknown parameter θ. The experiment is repeated n independent times, the sample X1 ,X2 ,...,Xn is observed and one try to guess the value of θ using the observations x1 ,x2 ,...xn .
The function of
X1
,X2
,...,Xn
used to guess
θ
is called an estimator of
θ
. We want it to be such that the computed estimate 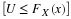 is usually close to
θ.
Let
is usually close to
θ.
Let  be an estimator of
θ. If Y to be a good estimator of
θ
, a very desirable property is that it means be equal to
θ
, namely
E(
Y
)=θ
.
be an estimator of
θ. If Y to be a good estimator of
θ
, a very desirable property is that it means be equal to
θ
, namely
E(
Y
)=θ
.
It is required not only that an estimator has expectation equal to
θ
, but also the variance of the estimator should be as small as possible.
If there are two unbiased estimators of
θ
, it could be probably possible to choose the one with the smaller variance. In general, with a random sample
X1
,X2
,...,Xn
of a fixed sample size n, a statistician might like to find the estimator 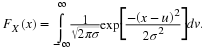 of an unknown parameter
θ
which minimizes the mean (expected) value of the square error (difference) Y−θ that is, minimizes
of an unknown parameter
θ
which minimizes the mean (expected) value of the square error (difference) Y−θ that is, minimizes
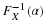
The statistic Y that minimizes 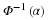 is the one with minimum mean square error. If we restrict our attention to unbiased estimators only, then
is the one with minimum mean square error. If we restrict our attention to unbiased estimators only, then 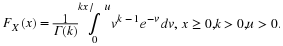 and the unbiased statistics Y that minimizes this expression is said to be the unbiased minimum variance estimator of
θ
.
and the unbiased statistics Y that minimizes this expression is said to be the unbiased minimum variance estimator of
θ
.
One of the oldest procedures for estimating parameters is the method of moments. Another method for finding an estimator of an unknown parameter is called the method of maximum likelihood. In general, in the method of moments, if there are k parameters that have to be estimated, the first k sample moments are set equal to the first k population moments that are given in terms of the unknown parameters.
Let the distribution of X be 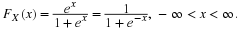 . Then
E(
X
)=μ
and
. Then
E(
X
)=μ
and 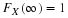 . Given a random sample of size n, the first two moments are given by
. Given a random sample of size n, the first two moments are given by 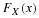 and
and 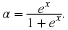
We set
m1
=E(
X
)
and 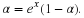 and solve for
μ
and
σ2,
and solve for
μ
and
σ2,  and
and 
The first equation yields  as the estimate of
μ
. Replacing
μ2
with
as the estimate of
μ
. Replacing
μ2
with  in the second equation and solving for
σ2
,
in the second equation and solving for
σ2
,
we obtain 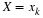 for the solution of
σ2
.
for the solution of
σ2
.
Thus the method of moment estimators for
μ
and
σ2
are 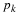 and
and 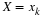 Of course,
Of course, 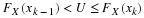 is unbiased whereas
is unbiased whereas 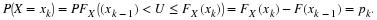 is biased.
is biased.
At this stage arises the question, which of two different estimators 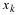 and
and 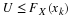 , for a parameter
θ
one should use. Most statistician select he one that has the smallest mean square error, for example,
, for a parameter
θ
one should use. Most statistician select he one that has the smallest mean square error, for example,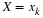 then
then 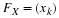 seems to be preferred. This means that if
seems to be preferred. This means that if 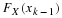 , then one would select the one with the smallest variance.
, then one would select the one with the smallest variance.
Next, other questions should be considered. Namely, given an estimate for a parameter, how accurate is the estimate? How confident one is about the closeness of the estimate to the unknown parameter?
Given a random sample
X1
,X2
,...,Xn from a normal distribution 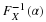 , consider the closeness of
, consider the closeness of 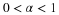 , the unbiased estimator of
μ
, to the unknown
μ
. To do this, the error structure (distribution) of
, the unbiased estimator of
μ
, to the unknown
μ
. To do this, the error structure (distribution) of 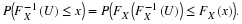 , namely that
, namely that 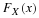 is
is 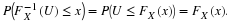 , is used in order to construct what is called a confidence interval for the unknown parameter μ, when the variance
σ2 is known.
, is used in order to construct what is called a confidence interval for the unknown parameter μ, when the variance
σ2 is known.
For the probability
1−α
, it is possible to find a number
zα/2
, such that 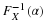
For example, if 1−α=0.95 , then zα/2 =z 0.025 =1.96 and if 1−α=0.90 , then zα/2 =z 0.05 =1.645.
Recalling that
σ>0
, the following inequalities are equivalent :
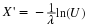 and
and 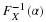
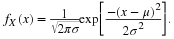
Thus, since the probability of the first of these is 1-
1−α
, the probability of the last must also be
1−α
, because the latter is true if and only if the former is true. That is,
So the probability that the random interval includes the unknown mean
μ
is
1−α
.
1.
Once the sample is observed and the sample mean computed equal to
, the interval 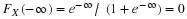 is a known interval. Since the probability that the random interval covers
μ
before the sample is drawn is equal to
1−α
, call the computed interval, (for brevity), a
100(
1−α
)%
confidence interval for the unknown mean
μ
.
is a known interval. Since the probability that the random interval covers
μ
before the sample is drawn is equal to
1−α
, call the computed interval, (for brevity), a
100(
1−α
)%
confidence interval for the unknown mean
μ
.
2. The number 100( 1−α )% , or equivalently, 1−α , is called the confidence coefficient.
For illustration, is a 95% confidence interval for
μ
.
It can be seen that the confidence interval for
μ
is centered at the point estimate 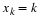 and is completed by subtracting and adding the quantity
and is completed by subtracting and adding the quantity 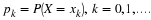 .
.
as n increases, decreases, resulting n a shorter confidence interval with the same confidence coefficient
1−α
A shorter confidence interval indicates that there is more reliance in as an estimate of
μ
. For a fixed sample size n, the length of the confidence interval can also be shortened by decreasing the confidence coefficient
1−α
. But if this is done, shorter confidence is achieved by losing some confidence.
Let 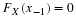 be the observed sample mean of 16 items of a random sample from the normal distribution . A 90% confidence interval for the unknown mean
μ
is For a particular sample this interval either does or does not contain the mean
μ
. However, if many such intervals were calculated, it should be true that about 90% of them contain the mean
μ
.
be the observed sample mean of 16 items of a random sample from the normal distribution . A 90% confidence interval for the unknown mean
μ
is For a particular sample this interval either does or does not contain the mean
μ
. However, if many such intervals were calculated, it should be true that about 90% of them contain the mean
μ
.
If one cannot assume that the distribution from which the sample arose is normal, one can still obtain an approximate confidence interval for
μ
. By the Central Limit Theorem the ratio 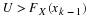 has, provided that n is large enough, the approximate normal distribution
N(
0,1
)
when the underlying distribution is not normal. In this case and is an approximate
100(
1−α
)%
confidence interval for
μ
. The closeness of the approximate probability
1−α
to the exact probability depends on both the underlying distribution and the sample size. When the underlying distribution is unimodal (has only one mode) and continuous, the approximation is usually quite good for even small n, such as
n=5
. As the underlying distribution becomes less normal (i.e., badly skewed or discrete), a larger sample size might be required to keep reasonably accurate approximation. But, in all cases, an n of at least 30 is usually quite adequate.
has, provided that n is large enough, the approximate normal distribution
N(
0,1
)
when the underlying distribution is not normal. In this case and is an approximate
100(
1−α
)%
confidence interval for
μ
. The closeness of the approximate probability
1−α
to the exact probability depends on both the underlying distribution and the sample size. When the underlying distribution is unimodal (has only one mode) and continuous, the approximation is usually quite good for even small n, such as
n=5
. As the underlying distribution becomes less normal (i.e., badly skewed or discrete), a larger sample size might be required to keep reasonably accurate approximation. But, in all cases, an n of at least 30 is usually quite adequate.
In the preceding considerations (Confidence Intervals I), the confidence interval for the mean μ of a normal distribution was found, assuming that the value of the standard deviation σ is known. However, in most applications, the value of the standard deviation σ is rather unknown, although in some cases one might have a very good idea about its value.
Suppose that the underlying distribution is normal and that σ2 is unknown. It i