Questions or comments concerning this laboratory should be directed to Prof. Charles A. Bouman, School of Electrical and Computer Engineering, Purdue University, West Lafayette IN 47907; (765) 494-0340; bouman@ecn.purdue.edu
Many of the phenomena that occur in nature have uncertainty and are best characterized statistically as random processes. For example, the thermal noise in electronic circuits, radar detection, and games of chance are best modeled and analyzed in terms of statistical averages.
This lab will cover some basic methods of analyzing random processes. "Random Variables" reviews some basic definitions and terminology associated with random variables, observations, and estimation. "Estimating the Cumulative Distribution Function" investigates a common estimate of the cumulative distribution function. "Generating Samples from a Given Distribution" discusses the problem of transforming a random variable so that it has a given distribution, and lastly, "Estimating the Probability Density Function" illustrates how the histogram may be used to estimate the probability density function.
Note that this lab assumes an introductory background in probability theory. Some review is provided, but it is unfeasible to develop the theory in detail. A secondary reference such as 1 is strongly encouraged.
The following section contains an abbreviated review of some of the basic definitions associated with random variables. Then we will discuss the concept of an observation of a random event, and introduce the notion of an estimator.
A random variable is a function that maps a set of possible outcomes of a random experiment into a set of real numbers. The probability of an event can then be interpreted as the probability that the random variable will take on a value in a corresponding subset of the real line. This allows a fully numerical approach to modeling probabilistic behavior.
A very important function used to characterize a random variable is the cumulative distribution function (CDF), defined as
Here, X is the random variable, and FX(x) is the probability that X will take on a value in the interval (–∞,x]. It is important to realize that x is simply a dummy variable for the function FX(x), and is therefore not random at all.
The derivative of the cumulative distribution function, if it exists, is known as the probability density function, denoted as fX(x). By the fundamental theorem of calculus, the probability density has the following property:
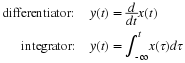
Since the probability that X lies in the interval (–∞,∞) equals one, the entire area under the density function must also equal one.
Expectations are fundamental quantities associated with random variables. The expected value of some function of X, call it g(X), is defined by the following.
Note that expected value of g ( X ) is a deterministic number. Note also that due to the properties of integration, expectation is a linear operator.
The two most common expectations are the mean μX and variance σX2 defined by
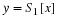
A very important type of random variable is the Gaussian or normal random variable. A Gaussian random variable has a density function of the following form:
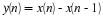
Note that a Gaussian random variable is completely characterized by its
mean and variance.
This is not necessarily the case for other types of distributions.
Sometimes, the notation 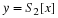 is used to identify X as
being Gaussian with mean μ and variance σ2.
is used to identify X as
being Gaussian with mean μ and variance σ2.
Suppose some random experiment may be characterized by a random variable X whose distribution is unknown. For example, suppose we are measuring a deterministic quantity v, but our measurement is subject to a random measurement error ε. We can then characterize the observed value, X, as a random variable, X=v+ε.
If the distribution of X does not change over time, we may gain further
insight into X by making several independent observations
 .
These observations Xi, also known as samples,
will be independent random variables and have the same distribution FX(x).
In this situation, the Xi's are referred to as i.i.d.,
for independent and identically distributed.
We also sometimes refer to
.
These observations Xi, also known as samples,
will be independent random variables and have the same distribution FX(x).
In this situation, the Xi's are referred to as i.i.d.,
for independent and identically distributed.
We also sometimes refer to  collectively as a
sample, or observation, of size N.
collectively as a
sample, or observation, of size N.
Suppose we want to use our observation 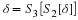 to estimate the mean and variance of X.
Two estimators which should already be familiar to you are the
sample mean and sample variance defined by
to estimate the mean and variance of X.
Two estimators which should already be familiar to you are the
sample mean and sample variance defined by
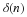
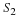
It is important to realize that these sample estimates are functions
of random variables, and are therefore themselves random variables.
Therefore we can also talk about the statistical properties of the estimators.
For example, we can compute the mean and variance of the sample mean
 .
.
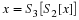
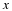
In both Equation 10.9 and
Equation 10.10 we have used the i.i.d. assumption.
We can also show that 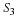 .
.
An estimate 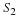 for some parameter a which has the property
for some parameter a which has the property
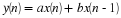 is said to be an unbiased estimate.
An estimator such that
is said to be an unbiased estimate.
An estimator such that 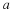 as N→∞
is said to be consistent.
These two properties are highly desirable because they imply that if a
large number of samples are used
the estimate will be close to the true parameter.
as N→∞
is said to be consistent.
These two properties are highly desirable because they imply that if a
large number of samples are used
the estimate will be close to the true parameter.
Suppose X is a Gaussian random variable with mean 0 and variance 1.
Use the Matlab function random or randn
to generate 1000 samples of X, denoted as
X1, X2, ..., X1000.
See the online help for the
random function.
Plot them using the Matlab function plot.
We will assume our generated samples are i.i.d.
Write Matlab functions to compute the sample mean and sample variance of
Equation 10.7 and Equation 10.8
without
using the predefined mean and var functions.
Use these functions to compute the sample mean
and sample variance of the samples you just generated.
Submit the plot of samples of X.
Submit the sample mean and the sample variance that you calculated. Why are they not equal to the true mean and true variance?
A linear transformation of a random variable X has the following form
where a and b are real numbers, and a≠0. A very important property of linear transformations is that they are distribution-preserving, meaning that Y will be random variable with a distribution of the same form as X. For example, in Equation 10.11, if X is Gaussian then Y will also be Gaussian, but not necessarily with the same mean and variance.
Using the linearity property of expectation, find the mean μY and variance σY2 of Y in terms of a, b, μX, and σX2. Show your derivation in detail.
First find the mean, then substitute the result when finding the variance.
Consider a linear transformation of a Gaussian random variable X with mean 0 and variance 1. Calculate the constants a and b which make the mean and the variance of Y 3 and 9, respectively. Using Equation 10.6, find the probability density function for Y.
Generate 1000 samples of X, and then calculate 1000 samples of Y by applying the linear transformation in Equation 10.11, using the a and b that you just determined. Plot the resulting samples of Y, and use your functions to calculate the sample mean and sample variance of the samples of Y.
Submit your derivation of the mean and variance of Y.
Submit the transformation you used, and the probability density function for Y.
Submit the plot of samples of Y and the Matlab code used to generate Y. Include the calculated sample mean and sample variance for Y.
Suppose we want to model some phenomenon as a random variable X with distribution FX(x). How can we assess whether or not this is an accurate model? One method would be to make many observations and estimate the distribution function based on the observed values. If the distribution estimate is “close” to our proposed model FX(x), we have evidence that our model is a good characterization of the phenomenon. This section will introduce a common estimate of the cumulative distribution function.
Given a set of i.i.d.
random variables 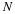 with CDF FX(x),
the empirical cumulative distribution function
with CDF FX(x),
the empirical cumulative distribution function 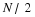 is defined as the following.
is defined as the following.
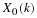
In words, 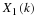 is the fraction of the Xi's which are less than or
equal to x.
is the fraction of the Xi's which are less than or
equal to x.
To get insight into the estimate 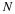 , let's compute its mean and
variance.
To do so, it is easiest to first define Nx as
the number of Xi's which are less than or equal to x.
, let's compute its mean and
variance.
To do so, it is easiest to first define Nx as
the number of Xi's which are less than or equal to x.
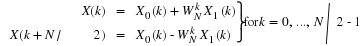
Notice that 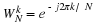 , so
, so
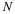
Now we can compute the mean of 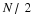 as follows,
as follows,
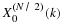
This shows that 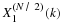 is an unbiased estimate of FX(x).
By a similar approach, we can show that
is an unbiased estimate of FX(x).
By a similar approach, we can show that
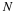
Therefore the empirical CDF 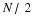 is both an unbiased and
consistent estimate of the true CDF.
is both an unbiased and
consistent estimate of the true CDF.
Write a function F=empcdf(X,t)
to compute the empirical CDF
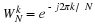 from the sample vector
X at the points specified in the vector t.
from the sample vector
X at the points specified in the vector t.
The expression sum(X<=s)
will return the number of
elements in the vector X which are less than or equal to s.
To test your function, generate a sample of Uniform[0,1] random variables
using the function X=rand(1,N).
Plot two CDF estimates: one using a sample size N=20, and one using
N=200.
Plot these functions in the range t=[-1:0.001:2]
, and on each plot
superimpose the true distribution for a Uniform[0,1] random variable.
Hand in your empcdf function and the two plots.
It is oftentimes necessary to generate samples from a particular distribution. For example, we might want to run simulations to test how an algorithm performs on noisy inputs. In this section we will address the problem of generating random numbers from a given distribution FX(x).
Suppose we have a continuous random variable