2013/05/21 14:23:17 -0500
Consider x∈αn. The goal of lossy compression 3 is to describe 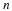 ,
also of length n but possibly defined over another reconstruction alphabet
,
also of length n but possibly defined over another reconstruction alphabet
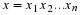 , such that the description requires few bits and the distortion
, such that the description requires few bits and the distortion
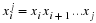
is small, where d(·,·) is some distortion metric.
It is well known that for every d(·,·) and distortion level D there is a minimum rate R(D),
such that 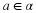 can be described at rate R(D). The rate R(D) is known as the rate distortion
(RD) function, it is the fundamental information theoretic limit of lossy
compression 3, 9.
can be described at rate R(D). The rate R(D) is known as the rate distortion
(RD) function, it is the fundamental information theoretic limit of lossy
compression 3, 9.
The invention of lossy compression algorithms has been a challenging problem for decades. Despite numerous applications such as image compression 24, 16, video compression 23, and speech coding 18, 4, 20, there is a significant gap between theory and practice, and these practical lossy compressors do not achieve the RD function. On the other hand, theoretical constructions that achieve the RD function are impractical.
A promising recent algorithm by Jalali and Weissman 13
is universal in the limit of infinite runtime.
Its RD performance is reasonable even with modest runtime.
The main idea is that the distortion version 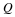 of the input x can be computed as follows,
of the input x can be computed as follows,
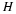
where β<0 is the slope at the particular point of interest in the RD function,
and 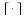 is the empirical conditional entropy of order k,
is the empirical conditional entropy of order k,
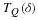
where uk is a context of order k, and as before 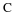 is the number of times that the
symbol a appears following a context uk in wn.
Jalali and Weissman proved 14
that when k=o(log(n)), the RD pair
is the number of times that the
symbol a appears following a context uk in wn.
Jalali and Weissman proved 14
that when k=o(log(n)), the RD pair  converges to the RD function asymptotically in n.
Therefore, an excellent lossy compression technique is to compute
converges to the RD function asymptotically in n.
Therefore, an excellent lossy compression technique is to compute  and then compress it.
Moreover, this compression can be universal. In particular, the choice of context order k=o(log(n)) ensures that
universal compressors for context tress sources can emulate the coding length of the empirical conditional entropy
and then compress it.
Moreover, this compression can be universal. In particular, the choice of context order k=o(log(n)) ensures that
universal compressors for context tress sources can emulate the coding length of the empirical conditional entropy
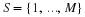 .
.
Despite this excellent potential performance, there is still a tremendous challenge.
Brute force computation of the globally minimum energy
solution 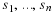 involves an exhaustive search over
exponentially many sequences and is thus infeasible.
Therefore, Jalali and Weissman rely on Markov chain Monte Carlo (MCMC) 12,
which is a stochastic relaxation approach to optimization. The crux of the matter is to define
an energy function,
involves an exhaustive search over
exponentially many sequences and is thus infeasible.
Therefore, Jalali and Weissman rely on Markov chain Monte Carlo (MCMC) 12,
which is a stochastic relaxation approach to optimization. The crux of the matter is to define
an energy function,
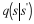
The Boltzmann probability mass function (pmf) is
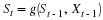
where t>0 is related to temperature in simulated annealing, and Zt is the normalization constant, which does not need to be computed.
Because it is difficult to sample from the Boltzmann pmf Equation 6.5
directly, we instead use a Gibbs sampler, which computes the marginal distributions
at all n locations conditioned on the rest of wn being kept fixed.
For each location, the Gibbs sampler resamples from the distribution of
wi conditioned on 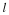 as induced by the joint pmf in Equation 6.5,
which is computed as follows,
as induced by the joint pmf in Equation 6.5,
which is computed as follows,
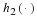
We can now write,
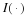
where 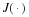 is the change in
is the change in 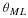 when yi=a is replaced by b, and
when yi=a is replaced by b, and
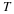 is the change in distortion.
Combining Equation 6.6 and Equation 6.7,
is the change in distortion.
Combining Equation 6.6 and Equation 6.7,
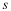
The maximum change in the energy within an iteration of MCMC algorithm is then bounded by
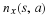
We refer to the resampling from a single location as an iteration, and group the n possible locations into super-iterations.[2]
During the simulated annealing, the temperature t
is gradually increased, where in
super-iteration i we use t=O(1/log(i)) 12, 13.
In each iteration, the Gibbs sampler modifies wn in a
random manner that resembles heat bath concepts in statistical physics. Although
MCMC could sink into a local minimum, we decrease the temperature slowly enough
that the randomness of Gibbs sampling eventually drives MCMC out of the local
minimum toward the set of minimal energy solutions, which includes 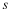 ,
because low temperature t favors low-energy wn.
Pseudo-code for our encoder appears in Algorithm 1 below.
,
because low temperature t favors low-energy wn.
Pseudo-code for our encoder appears in Algorithm 1 below.
Algorithm 1: Lossy encoder with fixed reproduction alphabetInput:xn∈αn, 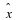 , β, c, rOutput: bit-stream Procedure:
, β, c, rOutput: bit-stream Procedure:
Initialize w by quantizing x with 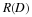
Initialize nw(·,·) using w
for r=1 to R do // super-iteration
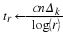 // temperature
// temperature
Draw permutation of numbers {1,...,n} at random
for r'=1 to n do
Let j be component t' in permutation
Generate new wj using 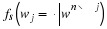
Update nw(·,·)[·]
Apply CTW to wn // compress outcome
Looking at the pseudo-code, it is clear that the following could be computational bottlenecks:
Initializing nw(·,·) - a naive implementation needs to scan the sequence wn (complexity O(n)) and initialize a data structure with 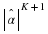 elements. Unless
elements. Unless 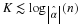 , this is super linear in n. Therefore, we recall that K=o(log(n)), and initializing nw(·,·) requires linear complexity O(n).
, this is super linear in n. Therefore, we recall that K=o(log(n)), and initializing nw(·,·) requires linear complexity O(n).
The inner loop is run rn times, and each time computing 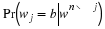 for all possible
for all possible 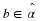 might be challenging. In particular, let us consider computation of Δd and ΔH.
might be challenging. In particular, let us consider computation of Δd and ΔH.
Computation of Δd requires constant time, and is not burdensome.
Computation of ΔH requires to modify the symbol counts for each context that was modified.
A key contribution by Jalali and Weissman
was to recognize that the array of symbol counts, nw(·,·),
would change in O(k) locations, where k is the context order. Therefore, each computation of ΔH
requires O(k) time. Seeing that 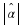 such computations per iteration are needed,
and there are rn iterations, this is
such computations per iteration are needed,
and there are rn iterations, this is 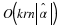 .
.
Updating nw(·,·) after wj is re-sampled from the Boltzmann distribution also requires
O(k) time. However, this step is performed only once per iteration, and not 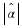 times.
Therefore, this step requires less computation than step (b).
times.
Therefore, this step requires less computation than step (b).
So far, we have described the approach by Jalali and Weissman to compress xn∈αn. Suppose instead that x∈Rn is analog. Seeing that MCMC optimizes wn over a discrete alphabet, it would be convenient to keep doing so. However, because 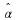 is finite, and assuming that square distortion is used, i.i.,
is finite, and assuming that square distortion is used, i.i., 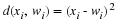 , we see that the distortion could be large.
, we see that the distortion could be large.
Fortunately, Baron and Weissman showed 6 that the following quantizer has favorable properties,
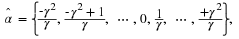
where γ is an integer that grows with n. That is, as γ grows the set 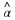 of reproduction levels quantizers a wider internal more finely. Therefore, we have that the probability that
some xi is an outlier, i.e., |xi|<γ, vanishes with n, and the effect of outliers on
of reproduction levels quantizers a wider internal more finely. Therefore, we have that the probability that
some xi is an outlier, i.e., |xi|<γ, vanishes with n, and the effect of outliers on
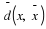 vanishes. Moreover, because the internal is sampled more finely as
γ increases with n, this quantizer can emulate any codebook with continuous levels,
and so in the limit its RD performance converges to the RD function.
vanishes. Moreover, because the internal is sampled more finely as
γ increases with n, this quantizer can emulate any codebook with continuous levels,
and so in the limit its RD performance converges to the RD function.
To evaluate the RD performance, we must first define the RD function. Consider a source X that generates a sequence xn∈Rn. A lossy encoder is a mapping e:Rn→C, where C⊂Rn is a codebook that contains a set of codewords in Rn. Let Cn(x,D) be the smallest cardinality codebook for inputs of length n generated by X such that the expected per-symbol distortion between the input xn and the codeword e(x)∈Cn(x,D) is at most D. The rate Rn(x,D) is the per-symbol log-cardinality of the codebook,
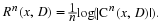
This is an operational definition of the RD function in terms of the best block code. In contrast, it can be shown that the RD function is equal to a minimization over mutual information, yielding a different flavor of definition 9, 3.
Having defined the RD function, we can describe the RD performance of the compression algorithm by Baron and Weissman for continuous valued inputs.
Theorem 8 Consider square error distortion, 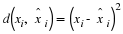 ,
let X be a finite variance stationary and ergodic source with RD function
,
let X be a finite variance stationary and ergodic source with RD function