2013/05/16 12:48:35 -0500
We have discussed several parametric sources, and will now start developing mathematical tools in order to investigate properties of universal codes that offer universal compression w.r.t. a class of parametric sources.
Consider a class Λ of parametric models, where the parameter set θ characterizes
the distribution for a specific source within this class, 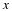 .
.
Consider the class of memoryless sources over an alphabet α={1,2,...,r}. Here we have
The goal is to find a fixed to variable length lossless code that is independent of θ, which is unknown, yet achieves
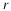
where expectation is taken w.r.t. the distribution implied by θ. We have seen for
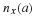
that a code that is good for two sources (distributions) p1 and p2 exists, modulo the one bit loss Equation 3.2. As an expansion beyond this idea, consider
where w(θ) is a prior.
Let us revisit the memoryless source, choose r=2, and define the scalar parameter
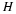
Then
and
Moreover, it can be shown that
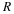
this result appears in Krichevsky and Trofimov 2.
Is the source X implied by the distribution p(x) an ergodic source?
Consider the event 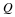 .
Owing to symmetry, in the limit of large n the probability of this event under p(x) must be
.
Owing to symmetry, in the limit of large n the probability of this event under p(x) must be 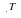 ,
,
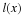
On the other hand, recall that an ergodic source must allocate probability 0 or 1 to this flavor of event. Therefore, the source implied by p(x) is not ergodic.
Recall the definitions of pθ(x) and p(x) in Equation 4.6 and Equation 4.7, respectively. Based on these definitions, consider the following,
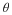
We get the following quantity for mutual information between the random variable Θ and random sequence X1N,
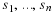
Note that this quantity represents the gain in bits that the parameter θ creates; more about this quantity will be mentioned later.
We now define the conditional redundancy,
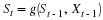
this quantifies how far a coding length function l is from the entropy where the parameter θ is known. Note that
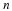
Denote by cn the collection of lossless codes for length-n inputs, and define the expected redundancy of a code l∈Cn by
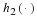
The asymptotic expected redundancy follows,
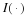
assuming that the limit exists.
We can also define the minimum redundancy that incorporates the worst prior for parameter,
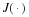
while keeping the best code. Similarly,
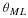
Let us derive Rn–,
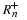
where Cn is the capacity of a channel from the sequence x to the parameter 4. That is, we try to estimate the parameter from the noisy channel.
In an analogous manner, we define
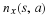
where Q is the prior induced by the coding length function l.
Note that
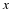
Therefore,
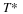
In fact, Gallager showed that Rn+=Rn–. That is, the min-max and max-min redundancies are equal.
Let us revisit the Bernoulli source pθ where θ∈Λ=[0,1]. From the definition of Equation 4.6, which relies on a uniform prior for the sources, i.e., w(θ)=1,∀θ∈Λ, it can be shown that there there exists a universal code with length function l such that
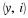
where h2(p)=–plog(p)–(1–p)log(1–p) is the binary entropy. That is, the redundancy is approximately log(n) bits. Clarke and Barron 1 studied the weighting approach,
and constructed a prior that achieves Rn–=Rn+ precisely for memoryless sources.
Theorem 5 1 For memoryless source with an alphabet of size r, θ=(p(0),p(1),⋯,p(r–1)),
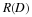
where On(1) vanishes uniformly as n→∞ for any compact subset of Λ, and
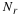
is Fisher's information.
Note that when the parameter is sensitive to change we have large I(θ), which increases the redundancy. That is, good sensitivity means bad universal compression.
Denote
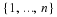
this is known as Jeffrey's prior. Using w(θ)=J(θ), it can be shown that Rn–=Rn+.
Let us derive the Fisher information I(θ) for the Bernoulli source,
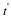
Therefore, the Fisher information satisfies
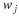 .
.
Recall the Krichevsky–Trofimov coding, which was mentioned in Example 4.2.
Using the definition of Jeffreys' prior Equation 4.26, we see that
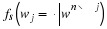 . Taking the integral over Jeffery's prior,
. Taking the integral over Jeffery's prior,
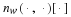
where we used the gamma function. It can be shown that
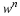
where
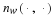
Similar to before, this universal code can be implemented sequentially. It is due to Krichevsky and Trofimov 2, its redundancy satisfies Theorem 5 by Clarke and Barron 1, and it is commonly used in universal lossless compression.
Let us consider – on an intuitive level – why 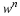 .
Expending
.
Expending 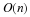 bits allows to differentiate between
bits allows to differentiate between 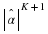 parameter vectors. That is, we would differentiate between each of the r–1 parameters with
parameter vectors. That is, we would differentiate between each of the r–1 parameters with 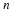 levels.
Now consider a Bernoulli RV with (unknown) parameter θ.
levels.
Now consider a Bernoulli RV with (unknown) parameter θ.
One perspective is that with n drawings of the RV,
the standard deviation in the number of 1's is 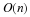 . That is,
. That is, 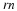 levels differentiate between
parameter levels up to a resolution that reflects the randomness of the experiment.
levels differentiate between
parameter levels up to a resolution that reflects the randomness of the experiment.
A second perspective is that of coding a sequence of Bernoulli outcomes with an imprecise parameter, where it is convenient to think of a universal code in terms of first quantizing the parameter and then using that (imprecise) parameter to encode the input x. For the Bernoulli example, the maximum likelihood parameter θML satisfies
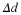
and plugging this parameter θ=θML into pθ(x) minimizes the coding length among all possible parameters, θ∈Λ. It is readily seen that
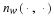
Suppose, however, that we were to encode with θ'=θML+Δ. Then the coding length would be
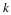
It can be shown that this coding length is suboptimal w.r.t. lθML(